Cluster Edition
The Cluster Edition is a product with high input speed and standard SQL that can process large data input / inquiries in a distributed environment that not even the Machbase Standard Edition can process, such as on multiple servers either on premise or in the cloud.
Why Should We Use the Cluster Edition?
Machbase offers Standard Edition which inputs time series data at extremely high speed. However, the following disadvantages exist:
- Because it consists of a single process, it lacks in high availability (HA).
- Because one process is dedicated to analyzing data, there is a limit to increasing the performance of large data analysis.
To overcome these shortcomings, there is a need for a higher end distributed product that can ensure availability and scalability when storing and analyzing large amounts of data. The Machbase Cluster Edition meets these requirements.
Terms
Host Represents one physical server, or one OS instance in the cloud/VM.
Node Represents the Machbase Process residing on the server.
The Process type is the same as the Node types below.
- Coordinator
- Deployer
- Lookup
- Broker
- Warehouse
Structure
In the Machbase Cluster Edition, several nodes that reside in the Host constitute one cluster.
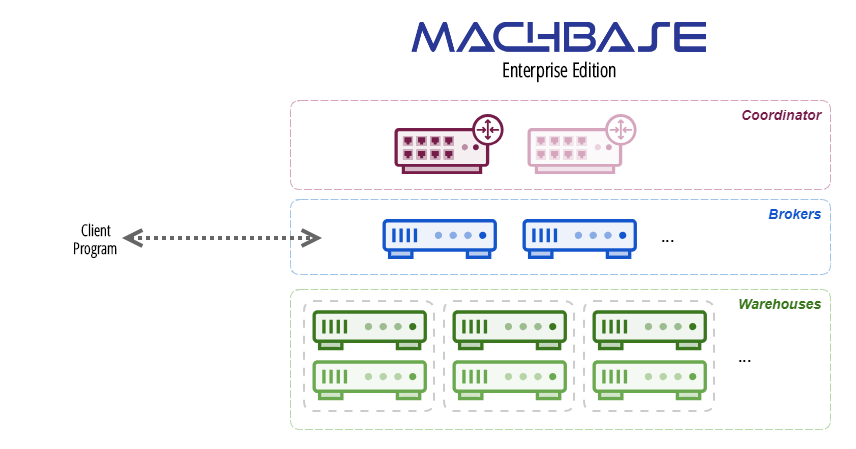
High Availability The service can be continued even if one of all the internal nodes is interrupted.
High Scalability Data storage can be distributed, and parallel analysis is possible from the distributed data, so
performance increases as the cluster grows.
Classifications of Node
Each Node can be classified as follows:
| Classification | Description | Process Name |
|---|---|---|
| Coordinator | The process of managing all general purpose servers and nodes | machcoordinatord |
| Deployer | The process that resides on each host Responsible for installing, upgrading, and monitoring the Broker / Warehouse. | machdeployerd |
| Lookup | The process of Lookup table data. | machlookupd |
| Broker | The process of welcoming an actual client program. Serves to distribute client data insert / data lookup queries to the warehouse. | machbased |
| Warehouse | The process that stores the actual data Stores some of the entire cluster data and executes the commands received from the Broker. | machbased |
Coordinator
Coordinator is a process that manages the state of all nodes, and can be a maximum of two.
First, the generated Coordinator is called the Primary Coordinator, and the other is called the Secondary Coordinator, and only the Primary Coordinator manages the state of all the Nodes.
When the Primary Coordinator is down, the Secondary Coordinator is upgraded to Primary Coordinator.
Special Node: Deployer
It is managed by the Coordinator, but it is simply a process that installs / removes Broker / Warehouse / Lookup Nodes.
Normally, only one Deployer can be added to the Host at a time when installing Nodes, but multiple Deployers can be added for installation performance.
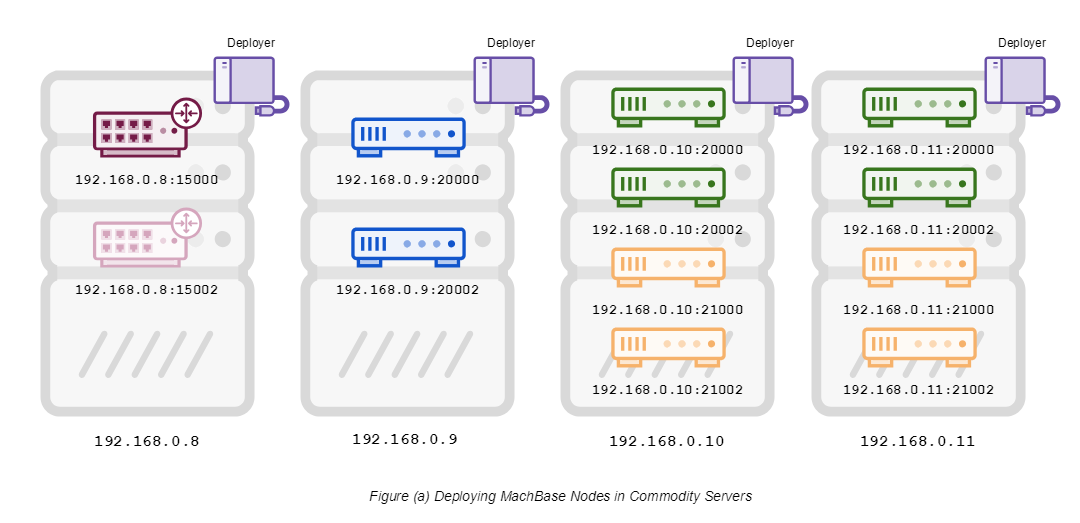
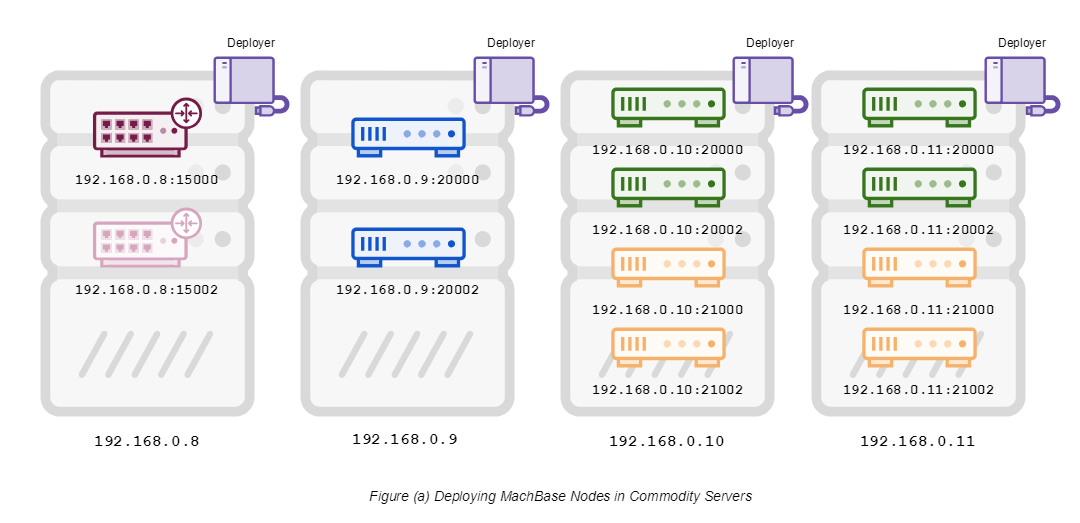
Example of Installation From Server Figure (a) below shows the installation of two Coordinators, two Brokers, four Warehouse Active, and four Warehouse Standby Nodes on four generic servers.
As shown in the figure, you can distinguish each node with ‘hostname: port’ followed by the host name of the general-purpose server and the assigned port number.
Lookup
Lookup is for data management in Lookup Table.
Broker
The Broker delivers the Client’s commands to the Warehouse, and then collects the results of the Warehouse and transmits them back into the Client.
- When entering data, the Broker makes sure the data enters evenly into the Warehouse.
- When retrieving data, the Broker fetches the data to the Warehouse and collects and delivers all the results.
The Broker does not have the data in the Log Table, but it has the data in the Volatile Table.
Warehouse
The Warehouse will store the Log Table data directly, and will act as the actual execution of the command delivered by the Broker.
Like the Broker, there is direct client access to the Warehouse, but the data can not be input / updated / deleted; the Warehouse data can only be retrieved.
Warehouse Group
The Warehouse can specify the Group to which it belongs.
- When the Broker inputs data, all Warehouses in the same Group receive the same records.
- Even if a specific Warehouse of the group is dropped, there are no issues with data retrieval.
- When a new Warehouse is added to a group, the same records are maintained through Replication.
Status of Warehouse Group
| Status | INSERT/APPEND | SELECT |
|---|---|---|
| Normal | O | O |
| Readonly | X | O |
The conditions that change to Readonly state are as follows.
- During INSERT / APPEND, if some Warehouses in the Group fail to be input
- Because there is a data inconsistency between the failed Warehouses and the successful Warehouses, the failed Warehouse is placed in the Scrapped state and the group is moved to the Readonly state to avoid receiving further input. (warning)
- When a new Warehouse is added
- If the input is received even while the replication process is in progress, the state is changed to the Readonly state because the end of the replication is unknown. (warning)
Node Port Management
Each Node must have several ports open, which are distinguished as follows:
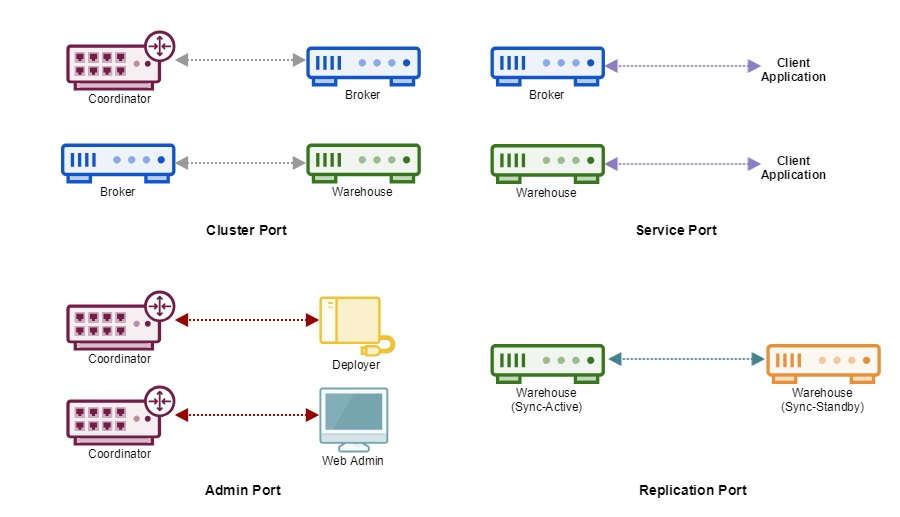
| Port Classification | Description | Required Node |
|---|---|---|
| Service Port | Port directly connected by client | Broker / Warehouse |
| Cluster Port | Port for communication between Nodes | All Nodes |
| Replication Port | Port for communication between warehouses for replication | Warehouse |
| Admin Port | Port for communication for management purpose | Coordinator / Deployer |
Commands That Can Be Executed After Direct Connection
The following table lists the possible and not possible commands to connect directly to each Node. All nodes are accessible via the client, but there are queries that are not possible depending on the type of Node.
| Broker (Leader) | Broker (non-leader) | Warehouse Standby | |
|---|---|---|---|
| Client Connection | O | O | O |
| DDL | O | X | X |
| DELETE | O | O | X |
| INSERT | O | O | X |
| APPEND | O | O | X |
| SELECT | O | O | O |
Save/Select Data
Machbase Cluster Edition can distribute the data and collect the results computed by distributed query execution. This section explains how to store and lookup the table type.
Save Data
Log Table
When data is entered into the Log Table through the Broker, it is distributed to all warehouses. (The data is not stored in the Broker that performs the input.) The Coordinator determines the database size of each warehouse, and the Broker distributes the data based on that.
If data is entered directly into the Log Table via the Warehouse, it is stored only in the corresponding Warehouse. Can be selected to avoid performance degradation due to distributed algorithm and network bottleneck.
Volatile Table
When a Broker enters data into a Volatile Table, it is stored in the corresponding Broker. In other words, no data is entered or synchronized with other Brokers.
The reason for not supporting replication for Volatile Tables is that if it matches the characteristics of the Volatile Table able to DELETE, it affects the replication performance.
Volatile tables are created only in the Broker, so they can not be entered in the Warehouse.
Lookup Table
When data is entered into the lookup table through a broker, the entered data is stored in the lookup node and replicated to other brokers through replication.
Tag Table
It is the same as the storage method of the log table. However, when entering data including a new TagID, it can only be entered through the Leader Broker.
Select Data
Log Table
When you view the data in the Log Table through the Broker, queries are distributed to all Warehouses. Each Warehouse actually performs the query, exchanging intermediate results between the Warehouses if necessary. The Broker collects the partial results generated in this way and returns the final result.
When viewing the data in the Log Table through the Warehouse, the query is executed only in the corresponding warehouse. This process is identical to query execution in the Fog Edition.
Lookup / Volatile Table
When viewing data in a Volatile Table through a Broker, the query is executed only by the Broker. This process is identical to query execution in the Fog Edition.
JOIN can not be done through the Warehouse, because Volatile Tables are not created.
JOIN Between Two Tables
When joining a Log Table and a Volatile Table through a Broker, the connected Broker and the rest of the Warehouse execute the query at the same time. The Broker distributes the results of the Volatile table to the Warehouse.
The Warehouse JOINs the data delivered by the broker and returns the result. The Broker collects the partial results generated in this way and returns the final result.
JOIN can not be done through the warehouse, because volatile tables are not created.
Replication
Replication refers to the process of replicating the same node in preparation for failure of an existing node.
Coordinator Replication
Up to two Coordinators can be created in Cluster Edition.
Both Coordinators continuously maintain Cluster Node information.
Even if either end abnormally, the remaining Coordinator can continue managing the Cluster Node.
When the Primary Coordinator is restarted, the existing secondary coordinator is upgraded to primary and the restarting coordinator becomes secondary.
Lookup Replication
Basically, the Lookup Master manages the Lookup Table data, but you can add a Lookup Slave to duplicate the data.
Broker Replication
The Broker is not a Replication target.
Therefore, the data record of the Volatile Table in Broker A is not kept the same in Broker B. (not synchronized)
However, because the table / index scheme of the entire Cluster are all the same, if the Volatile Table VOL_TBL1 exists with Broker A, Volatile Table VOL_TBL1 also exists with Broker B.
Warehouse Replication
If a new Warehouse is added to the Group, the Warehouse is replicated through the following process.
1. The Coordinator starts DDL replication to the new Warehouse.
2. Group switches to Readonly state.
3. One of the Warehouses in the group starts data replication to the new warehouse.
4. When the data replication is completed, the group is switched to the Normal state.
In the case of data insert, the Broker guarantees redundancy by sending the same data to the same Group.
How To Recover
Even if the Node terminates abnormally, the service can be continued in the following manner.
For more information, refer to the Operations Guide.
| Type | Fail-over Method |
|---|---|
| Coordinator | Even if the Primary Coordinator is abnormally terminated, the Secondary Coordinator becomes the Primary Coordinator and the cluster management can continue. Even if the Coordinator is terminated in the worst case scenario, the entire service (data insert / inquiry) can be continued without the cluster management. (Of course, when the Broker or Warehouse is shut down at this time, you can not manage the cluster.) |
| Deployer | Node operation (ADD, REMOVE ..) can not be performed on the corresponding Host, and statistical information of the host can not be collected. |
| Lookup | When a failure occurs in Lookup Master, Lookup Monitor automatically detects and changes one of the Lookup Slaves to Lookup Master to enable continuous service use. If there is no Lookup Slave in the past, it is recommended that at least one Lookup Slave exists for stable HA because data replication is not possible. |
| Broker | Even if the Broker is terminated, the service can continue if another Broker exists. However, because the connection to the client that has been terminated is disconnected, it must be reconnected to another Broker. |
| Warehouse | If there is another / other Warehouse (s) in the Group, the Warehouse (s) will participate in SELECT and APPEND. |
Not Supported Features
Query Statement
TABLESPACE
Currently, the Cluster Edition does not distinguish between table spaces.
BACKUP / MOUNT
Currently, the Cluster Edition does not distinguish between databases.
LOAD IN FILE
The ability to read and distribute CSV files is currently not implemented.
ALTER TABLE FORGERY CHECK
Result File can not be collected in one place as client’s user data is checked for any changes.
Clause/Function
UNION ALL
Execution units are complex and are currently not supported.
GROUP_CONCAT() function
The entire contents of the CONCAT for the subgroups collected by each Warehouse can not be processed as a simple accumulation. (ORDER BY in GROUP CONCAT)
TS_CHANGE_COUNT() function
The TS_CHANGE_COUNT results for the subgroups collected in each Warehouse can not be processed as simple accumulations.
In addition, TS_CHANGE_COUNT () is significant if the entire result is sorted, but if the results are distributed in the Warehouse, it is meaningless.
Supported Hardware and Operating Systems
| CPU | Intel Core i Series (Nehalem~) or higher recommended |
|---|---|
| Memory | 2 GB or more recommended for each Node to be installed |
| Operating System | Linux (Any distribution) |