Blog
Blog
“ Mach Speed Horizontally Scalable Time series database. ”
Comparing Time-Series Database Architectures: Machbase vs. InfluxDB
- Introduction
- Comparison of Architectures
- The implementation language / Client interface
- Data Model
- Query Language
- Conclusion
Introduction
For those interested in comparing databases specialized for time-series data, this time, we will delve into an architecture comparison with InfluxDB.
Although the performance comparison is based on past versions (approximately 3–4 years ago), with Machbase DB notably excelling, there is currently no available data for a comparison of the latest versions. Additionally, both products have undergone significant changes since then, making it less ideal to draw conclusions at the current juncture. Therefore, it is advisable to consider this information as reference material.
Machbase is a DBMS developed with the aim of facilitating quick input, retrieval, and statistical analysis of time-series sensor data.
It supports various environments ranging from edge devices like Raspberry Pi to single-server setups and multi-server clusters.
It features specialized capabilities and architecture tailored for processing time-series sensor data and machine logs.
It is an open-source time-series DBMS being developed by InfluxData.
It is one of the most renowned products for processing time-series data. InfluxDB also supports clustering.
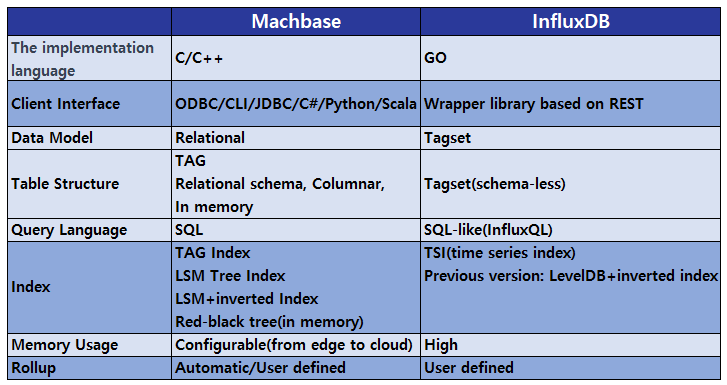
Both Machbase and InfluxDB are specialized products tailored for processing time-series data, and their key characteristics can be summarized as follows:
In this post, the analysis will primarily prioritize usability features. Detailed information regarding indexes, internal structures, and content related to performance testing will be covered after conducting performance tests and will be discussed in future updates.
Machbase Neo’s Architecture
Machbase has its server code written in C, while the ODBC/CLI and embedded tools within the server are written in C++. Additionally, libraries for JDBC, C#, and Scala are implemented in their respective languages. The communication protocol between the server and clients is designed using a dedicated protocol to support common RDBMS interfaces such as Prepare/Bind/Execute. This implementation is carefully designed for optimal efficiency.
The C# connector is publicly available on the Machbase Github repository, allowing anyone to reference its internal implementation.
InfluxDB is written in the GO programming language, and its communication protocol is based on REST. It provides client libraries in various languages, although interfaces like Prepare/Bind/Execute are not offered. When examining the source code of prominent C++ client libraries (linked on the InfluxDB website), it becomes apparent that all operations are translated into REST and transmitted. The implementation uses the open-source HTTP library, curl.
{
CURLcode response;
long responseCode;
curl_easy_setopt(curlHandle.get(), CURLOPT_POSTFIELDS, post.c_str());
curl_easy_setopt(curlHandle.get(), CURLOPT_POSTFIELDSIZE, (long) post.length());
response = curl_easy_perform(curlHandle.get());
curl_easy_getinfo(curlHandle.get(), CURLINFO_RESPONSE_CODE, &responseCode);
if (response != CURLE_OK) {
throw std::runtime_error(curl_easy_strerror(response));
} if (responseCode < 200 || responseCode > 206) {
throw std::runtime_error("Response code : " + std::to_string(responseCode)); }
}
A REST-based interface offers greater convenience in web environments. It allows easy transmission of queries from web servers and convenient data input from a multitude of sensors into the time-series database. Of course, Machbase also supports REST, so this can’t be seen as a unique advantage of Influx.
However, in cases where a small number of sensor data generates a massive amount of data very rapidly — for instance, with sensors like vibration sensors that produce data at very short intervals — Machbase’s unique APIs like SQLAppend, or common interfaces like Prepare-execute, Array-Binding, and Batch execute in the ODBC interface, prove highly efficient. Conversely, for InfluxDB, where all protocols are REST-based, achieving the same level of efficiency can be challenging. Therefore, in environments where continuous large-scale data is generated at short intervals, InfluxDB becomes less efficient.
Performance testing related to this aspect will be conducted in the future.
(Note: The translation provided maintains the original structure and meaning of the text, but slight modifications might be necessary depending on the context in which this translation will be used.)
Machbase supports a relational model. For tables designed for sensor data processing, such as TAGs, in addition to mandatory columns (sensor ID, input time, input value) created during table creation, additional necessary columns can be defined. These must be defined using Data Definition Language (DDL).
On the other hand, InfluxDB supports a semi-structured data format known as “tagset.” A single record is divided into key, tags, and a value list. Indexing is only possible for tags. All data inherently includes the input time column, without needing explicit specification. Even if the “time” column is not selected during a “SELECT” query, it is automatically included in the data, ensuring its presence in query results. In InfluxDB, the concept corresponding to a table is referred to as a “series.” Since there is no explicit Data Definition Language (DDL) for creating series, I will elaborate based on the provided query below. For this query, there is no need for a table creation statement. (There are no table creation queries in the provided query.)
It might sound unfamiliar, right? When translated into a Machbase query (including table and index creation DDL):
CREATE INDEX treasures_captain_id on treaures(captian_id);
INSERT INTO treasures VALUES ('pirate_king', 2);
Yes, all column names are included in the insert statement. In InfluxDB, since there is no schema, column names need to be explicitly specified during insertion. And
Furthermore, there is a space between the front “captain_id” and the back “value.” The column=value clause before the space (i.e., captain_id=pirate_king) represents the tag clause, and indexing is done only for these values. This index can also be applied in a nested manner.
These values are indexed for both captain_id and other_tag, whereas the space-separated values “value” and “value2” are input as non-indexed values. When conducting queries involving non-indexed values, the search tends to be slow since it involves a full scan query, which is expected. However, for columns that are not indexed, you cannot use the GROUP BY clause. The GROUP BY clause can only be applied to tag columns.
In this manner, the key-value data model configured in the form of column=value and tag=value is referred to as “tagset” in InfluxDB. This stands as a distinguishing factor from the relational model liked Machbase.
Machbase provides additional syntax in SQL queries to accommodate the characteristics of time-series data. This allows users familiar with SQL to use it with relative ease. In contrast, InfluxDB has transformed its query language to be more similar to NoSQL compared to Machbase.
Let’s take a look at simple queries and their results.
name: h2o_feet
--------------
time count
1970-01-01T00:00:00Z 15258
Yes, even if the “time” column is not included in the SELECT query’s column list, it is forcefully inserted, leading to the output of meaningless values. While the values corresponding to column names are enclosed in double quotation marks, it doesn’t seem too challenging to comprehend.
In the past, they had a query language called Flux, but it is undergoing a transition to a SQL-like query language as described earlier.
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "foo")
When translated into Machbase SQL:
FROM metrics
WHERE measurement = 'foo' DURATION 1 hour;
I will conclude the part of the post that covers interface details at this point. While both products are developed with the aim of efficiently processing time-series data, Machbase endeavors to support relational databases and DBMS standard interfaces to the fullest extent, while InfluxDB exhibits features more aligned with NoSQL characteristics.
To summarize:
I will conclude the part of the post that covers interface details at this point. While both products are developed with the aim of efficiently processing time-series data, Machbase endeavors to support relational databases and DBMS standard interfaces to the fullest extent, while InfluxDB exhibits features more aligned with NoSQL characteristics.
- Machbase is implemented in C and supports traditional DB interfaces like ODBC/JDBC, while InfluxDB is implemented in Go. It operates with a REST-based interface and a scripting-like structure, and it does not function with Prepare/Bind/Execute.
- Machbase operates as a relational database, adhering to schemas defined using DDL. This aligns with the conventional appearance of DBMS. In contrast, InfluxDB takes a different approach. It employs its unique data model called “tagset,” and lacks a DDL. Instead, it performs real-time column data parsing.
- Machbase supports extended syntax in its SQL-based query language, and InfluxDB offers a similar approach, although it operates in a manner closer to NoSQL.
While we regret not being able to delve into performance measurements through actual architectural comparisons due to time constraints, we assure you that this topic will be covered in the future.
Feel free to reach out if you have any questions or if there are further aspects you’d like to compare.
Thank you.
Machbase CRO, Grey Shim