DDL
CREATE TABLE
Syntax
create_table_stmt:
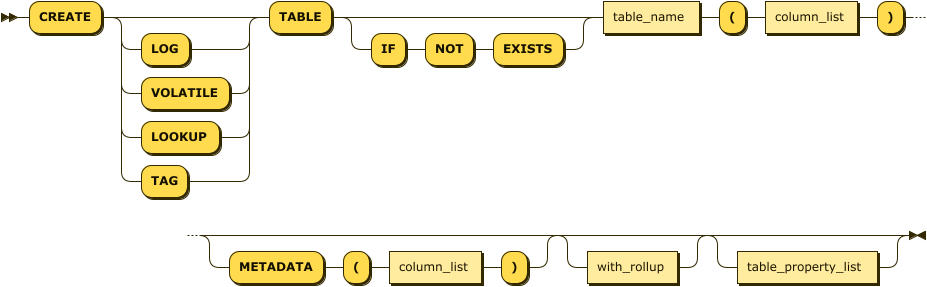
column_list:

column_property_list:
table_property_list:
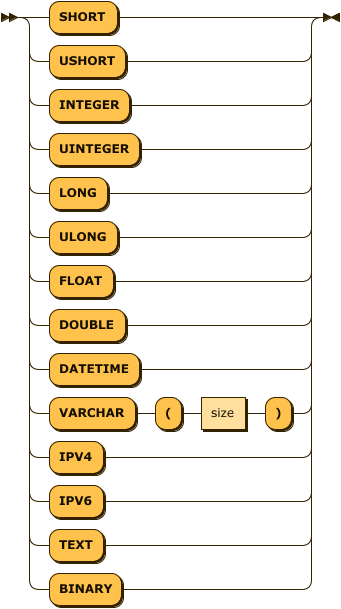
column_type:
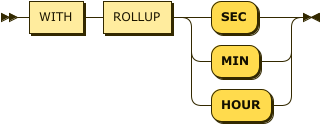
with_rollup:
LOG 테이블 생성 예제
-- create log table 예제
CREATE TABLE ctest (id INTEGER, name VARCHAR(20), sipv4 IPV4, dipv6 IPV6, comment TEXT);TAG 테이블 생성 예제
태그 테이블 생성시 반드시 PRIMARY KEY, BASETIME, SUMMARIZED 컬럼이 존재해야 한다.
-- create tag table 예제
CREATE TAG TABLE tag (name VARCHAR(20) PRIMARY KEY, time DATETIME BASETIME, value DOUBLE SUMMARIZED);
CREATE TAG TABLE tag (name VARCHAR(20) PRIMARY KEY, time DATETIME BASETIME, value DOUBLE SUMMARIZED, value2 FLOAT, int_column INT);
CREATE TAG TABLE tag (name VARCHAR(20) PRIMARY KEY, time DATETIME BASETIME, value DOUBLE SUMMARIZED, value2 FLOAT) METADATA (i1 INT);테이블 및 컬럼 이름
테이블 이름 또는 컬럼 이름은 영숫자(alphanumeric characters) 로 이루어진다. 특수문자를 사용하기 위해서는 쌍따옴표(") 를 사용한다.
CREATE TABLE special_tbl ( "with.dot" INTEGER );IF NOT EXISTS
테이블이 있는 경우 오류가 발생하지 않도록 한다. 그러나 기존 테이블의 구조가 CREATE TABLE 문에 표시된 구조와 동일한지는 확인하지 않는다.
같은 타입의 테이블에 대해서만 해당 기능이 동작한다.
테이블 종류
| 테이블 종류 | 설명 |
|---|---|
| LOG | CREATE TABLE 사이에 아무런 키워드를 넣지 않았다면 Log Table이 생성된다. |
| VOLATILE | VOLATILE_TABLE은 모든 데이터가 임시 메모리에 상주하는 임시 테이블이며 로그 테이블을 조인하여 결과를 향상시킵니다만, Machbase 서버가 종료 되자마자 사라집니다. |
| LOOKUP | VOLATILE_TABLE과 마찬가지로 LOOKUP_TABLE은 메모리의 모든 데이터를 저장함으로써 빠른 쿼리 처리를 수행 할 수 있습니다. |
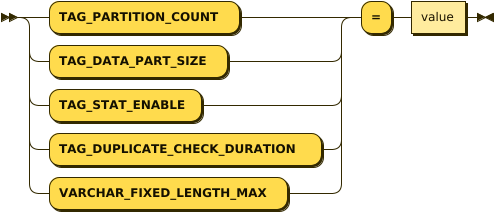
테이블 프로퍼티(Table Property)
Table에 대한 속성을 지정한다.
| 프로퍼티 이름 | 사용 가능한 테이블 종류 |
|---|---|
| TAG_PARTITION_COUNT | TAG TABLE |
| TAG_DATA_PART_SIZE | TAG TABLE |
| TAG_STAT_ENABLE | TAG TABLE |
| TAG_DUPLICATE_CHECK_DURATION | TAG TABLE |
| VARCHAR_FIXED_LENGTH_MAX | TAG table |
TAG_PARTITION_COUNT(Default:4)
TAG Table에 대해 지원되는 속성으로 TAG 테이블을 내부적으로 몇 개의 파티션 테이블에 저장할 것인지 결정한다. TAG의 수나 서버의 성능에 따라 설정하여야 한다.
TAG_DATA_PART_SIZE(Default:16MB)
TAG Table에 대해 지원되는 속성으로 파티션 테이블 별 데이터 사이즈를 결정한다.
TAG_STAT_ENABLE(Default:1)
TAG Table에 대해 지원되는 속성으로 TAG ID 별 통계 정보 저장 여부를 결정한다.
TAG_DUPLICATE_CHECK_DURATION(Default:0, Max:43200)
TAG Table에 대해 지원되는 속성으로 현재 시스템시간을 기준으로 중복 제거가 가능한 기간을 분단위로 설정한다. 현재 시스템시간으로부터 설정된 기간 이내의 데이터에 한해서 중복을 제거할 수 있으며 0일 경우 중복제거를 수행하지 않는다.
VARCHAR_FIXED_LENGTH_MAX (Default: 15, Max: 127)
내부 파일에 저장할 VARCHAR 컬럼의 최대 길이를 지정한다.
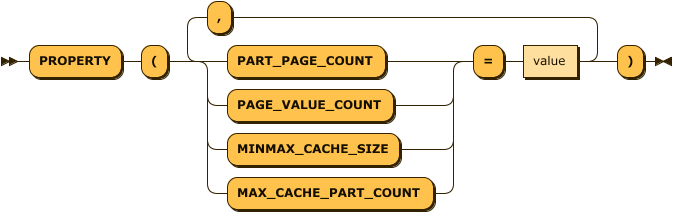
컬럼 프로퍼티(Column Property)
Column에 대한 속성을 지정한다.
| 프로퍼티 이름 | 사용 가능한 테이블 종류 |
|---|---|
| PART_PAGE_COUNT | LOG TABLE |
| PAGE_VALUE_COUNT | LOG TABLE |
| MAX_CACHE_PART_COUNT | LOG TABLE |
| MINMAX_CACHE_SIZE | LOG TABLE |
PART_PAGE_COUNT
이 프로퍼티는 하나의 파티션이 가지는 Page의 개수를 나타낸다. 하나의 파티션이 가지는 Value의 개수는 PART_PAGE_COUNT * PAGE_VALUE_COUNT가 된다.
PAGE_VALUE_COUNT
이 프로퍼티는 하나의 Page가 가지는 Value의 개수를 나타낸다.
MAX_CACHE_PART_COUNT (Default : 0)
이 프로퍼티는 성능 향상을 위한 캐시 영역을 설정하는 것이다.
마크베이스 가 파티션에 접근할 때 해당 파티션의 메타 정보를 메모리에 담고 있는 구조체를 먼저 찾게 되는데, 몇 개의 파티션 정보를 메모리에 담고 있을지 결정한다. 크면 클수록 성능에 도움이 될 것이나, 메모리 사용량이 늘어난다. 최소값은 1 최대값은 65535이다.
MINMAX_CACHE_SIZE (Default : 10240)
이 프로퍼티는 해당 Column의 MINMAX를 위한 캐시 메모리를 얼마나 사용할 것인지 지정하는 것이다. 0번째 Hidden Column인 _ARRIVAL_TIME의 경우 기본적으로 100MB으로 지정이 된다. 하지만 다른 Column들은 기본적으로 10KB로 지정되어 있다. 이 크기는 Table의 생성 이후에도 “ALTER TABLE MODIFY” 구문을 통해서 이 값은 변경이 가능하다.
NOT NULL Constraint
컬럼 값에 NULL을 허용하지 않을 경우 NOT NULL을 지정하고, 허용할 경우(Default)에는 생략한다.
테이블 생성 이후에 정의된 이 제약조건을 삭제하거나 추가하기 위해서는 ALTER TABLE MODIFY COLUMN 명령으로 제약조건을 변경할 수 있다.
-- 컬럼 c1은 not null로, c2는 not null 제약 조건 없이 생성한다.
CREATE TABLE t1(c1 INTEGER NOT NULL, c2 VARCHAR(200));Pre-defined System Columns
Create Table 문을 이용하여 테이블을 생성하면 시스템은 두 개의 사전 정의된 시스템 컬럼을 추가로 생성한다. _ARRIVAL_TIME 및 _RID컬럼이다.
_ARRIVAL_TIME 컬럼은 DATETIME 타입의 컬럼으로 INSERT 문이나 AppendData로 데이터를 삽입하는 시점의 시스템 time을 기준으로 삽입되며, 해당 값은 생성된 레코드의 unique key로 사용될 수 있다. 이 컬럼의 값은 순서가 보장되는 경우(과거-현재 순으로) machloader나 INSERT 문에서 값을 지정하여 삽입할 수 있다. DURATION 조건절을 이용하여 데이터를 검색할 경우, 이 컬럼의 값을 기준으로 데이터를 검색한다.
_RID 컬럼은 특정 레코드가 갖는 유일한 값으로 시스템이 생성한다. 이 컬럼의 데이터 타입은 64bit 정수이며, 이 컬럼에 대해서는 사용자가 값을 지정할 수 없고 인덱스도 생성할 수 없다. 데이터 INSERT시에 자동으로 생성된다. _RID 컬럼의 값으로 레코드를 검색할 수 있다.
create volatile table t1111 (i1 integer);
Created successfully.
Mach> desc t1111;
----------------------------------------------------------------
NAME TYPE LENGTH
----------------------------------------------------------------
_ARRIVAL_TIME datetime 8
I1 integer 4
Mach>insert into t1111 values (1);
1 row(s) inserted.
Mach>select _rid from t1111;
_rid
-----------------------
0
[1] row(s) inserted.
Mach>select i1 from t1111 where _rid = 0;
i1
--------------
1
[1] row(s) selected.Min Max Cache
Min-Max Cache 개념
일반적으로 Disk DBMS에서는 특정 값을 인덱스를 활용하여 검색할 경우 해당 인덱스가 포함된 디스크 영역에 대해 접근하고, 해당 값이 포함된 최종 디스크 페이지를 찾아가도록 구현되어 있다.
반면, 마크베이스는 시계열 정보를 유지하기 위해 시간순으로 파티션 되어있는 구조이며, 이것은 특정한 하나의 인덱스 정보가 시간순으로 조각조각의 파일로 나누어져 있다는 의미이다. 따라서, 마크베이스의 인덱스를 이용할 때는 이러한 파티션으로 조각나 있는 인덱스 파일을 순차적으로 검색한다.
만일 검색해야 할 대상 데이터의 범위가 1000개의 파티션으로 나뉘어져 있다면 1000번의 파일을 매번 열어서 검색해야 한다는 의미이다. 비록 효율적인 컬럼형 데이터베이스 구조로 설계되어 있긴 하나, 이러한 I/O 비용이 인덱스 파티션 개수의 크기에 비례하기 때문에 그 성능을 향상하기 위한 방법이 MINMAX_CACHE 구조이다.
이 MINMAX_CACHE는 해당 파티션의 인덱스 파일 정보를 메모리에 담고 있는 구조체로서 해당 컬럼의 최소 및 최대 값을 메모리에 유지하는 연속된 메모리 공간이다. 이런 구조를 유지함으로써 특정 값이 포함된 파티션을 검색할 경우 그 값이 해당 인덱스의 최소값 보다 작거나 최대 값보다 클 경우에는 아예 해당 파티션을 건너뛸 수 있기 때문에 고성능의 데이터 분석이 가능해진다.
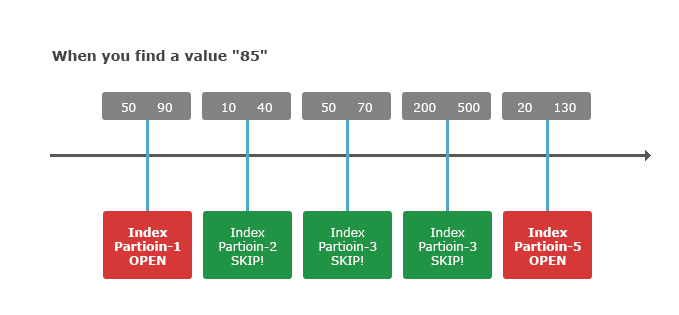
위의 그림에서 볼 수 있듯이 85라는 값을 찾기 위해서 5개의 파티션 중에서 MIN/MAX에 포함된 1번과 5번 파티션만을 실제로 검색하게 되며, 2, 3, 4 번 파티션은 아예 건너뛰는 모습을 볼 수 있다.
Min-Max Cache 컬럼
테이블 생성 시에 특정 컬럼에 대해 MINMAX Cache를 사용할 것인지 결정할 수 있다.
만일 이 컬럼이 minmax_cache_size가 0이 아닌 값으로 설정되었으면, 해당 컬럼에 인덱스 검색 시 MINMAX Cache가 동작하게 되며, MINMAX_CACHE_SIZE = 0일 경우에는 동작하지 않는다.
이런 MINMAX Cache를 사용할 때 다음과 같은 사항에 주의한다.
- MINMAX Cache 는 해당 컬럼에 인덱스를 명시적으로 생성하지 않아도 적용된다.
- 모든 컬럼의 default는 MINMAX_CACHE_SIZE가 10KB로 설정되있고 Alter Table 구문을 활용하여 적정한 크기의 메모리 크기를 재설정할 수 있다.
- 숨어있는 컬럼인 _arrival_time은 디폴트로 100MB이며, 자동으로 MINMAX Cache 메모리를 사용한다.
- VARCHAR 타입의 경우에는 MINMAX Cache 의 대상이 되지 않는다. 따라서 VARCHAR 타입을 명시적으로 캐시 사용 여부를 지정하면, 에러가 발생한다.
- 해당 테이블이 하나 생성될 때 프로퍼티에 설정된 MINMAX_CACHE_SIZE 만큼 최대 메모리가 더 사용될 수 있다. 파티션 개수가 늘수록 메모리가 점진적으로 늘어나 위의 최대 메모리만큼 늘어난다.
- 만일 해당 테이블에 레코드가 하나도 들어있지 않으면, MINMAX Cache 메모리는 전혀 할당되지 않는다.
아래는 실제 MINMAX를 활용한 테이블 생성 예를 나타낸다.
-- VARCHAR에 대한 MINMAX_CACHE_SIZE = 0은 의미상으로 허용된다.
CREATE TABLE ctest (id INTEGER, name VARCHAR(100) PROPERTY(MINMAX_CACHE_SIZE = 0));
Created successfully.
Mach>
-- id 컬럼에 캐시가 적용되었다.
CREATE TABLE ctest2 (id INTEGER PROPERTY(MINMAX_CACHE_SIZE = 10240), name VARCHAR(100) PROPERTY(MINMAX_CACHE_SIZE = 0));
Created successfully.
Mach>
-- id1, id2, id3 컬럼에 적용되었다.
CREATE TABLE ctest3 (id1 INTEGER PROPERTY(MINMAX_CACHE_SIZE = 10240), name VARCHAR(100) PROPERTY(MINMAX_CACHE_SIZE = 0), id2 LONG PROPERTY(MINMAX_CACHE_SIZE = 1024), id3 IPV4 PROPERTY(MINMAX_CACHE_SIZE = 1024), id4 SHORT);
Created successfully.
Mach>
-- Column단위로 MINMAX_CACHE_SIZE가 지정되거나, 0으로 설정되었다.
CREATE TABLE ctest4 (id1 INTEGER PROPERTY(MINMAX_CACHE_SIZE=10240), name VARCHAR(100) PROPERTY(MINMAX_CACHE_SIZE=0), id2 LONG PROPERTY(MINMAX_CACHE_SIZE=10240), id3 IPV4 PROPERTY(MINMAX_CACHE_SIZE=0), id4 SHORT);
Created successfully.
Mach>기본 키(Primary Key)
Volatile/Lookup 테이블의 컬럼에 부여할 수 있는 제약 사항으로, 해당 컬럼의 값이 중복되는 것을 방지한다. Volatile/Lookup 테이블이 항상 기본 키를 가지고 있을 필요는 없으나, 기본 키가 없으면 INSERT ON DUPLICATE KEY UPDATE 구문을 사용할 수 없다.
기본 키를 부여하면, 기본 키에 대응되는 레드-블랙 트리 인덱스가 생성된다.
Sequence Column
SEQUENCE for Lookup Table
Lookup 테이블의 Unique한 Record를 생성하고 Data의 입력 순서를 결정하기 위해 위해 Sequence가 추가되었다.
이 기능은 Lookup 테이블에서 datetime column을 사용하여 Record의 순서를 구분하는 방식을 사용했을 때
datetime 값이 중복될 경우 Record의 순서를 구분하기 어렵고 데이터 중복으로 인한 Application의 오류가 발생하는 등의 문제점을 해결하기 위해 추가되었다.
Lookup 테이블 생성 시 Sequence 설정
Create Table SQL 문으로 Lookup 테이블을 생성할 때 Sequence로 사용할 컬럼에 PROPERTY 절을 추가하여 Sequence를 설정하겠다고 명시하면 된다.
Sequence로 설정할 컬럼은 LONG datatype(64bit, unsigned)만 지원하며 이외의 datatype은 지원하지 않는다.
추가로, Sequence의 시작값을 설정할 수 있는데 1로 설정한 경우 Sequence가 1부터 시작이 된다. (0이나 음수는 지원 안함)
CREATE LOOKUP TABLE table_name (v1 LONG PROPERTY(SEQUENCE=1) PRIMARY KEY, v2 VARCHAR(10));Sequence 컬럼의 사용
Lookup 테이블의 Sequence 컬럼은 기본적으로 일반 Long 컬럼과 동일하게 사용이 가능하며 이렇게 사용할 경우 Sequence 값은 자동으로 증가하지 않는다.
Sequence 컬럼에 직접 값을 입력하는 것이 허용되며 심지어 중복 값을 입력하는 것도 가능하다.
대신, Sequence 기능을 사용하려면 nextval 이라는 새로 추가된 Sequence 전용 Function을 사용하여 Sequence값을 증가시키는 방식으로 사용해야 한다.
내부적으로는 Sequence로 설정된 컬럼의 값 중 가장 큰 값에 대해 저장하고 있기 때문에 이후에 nextval Function을 사용하여 입력할 때 Sequence 컬럼 값 중 가장 큰 값 + 1 의 값이 저장된다.
Sequence 컬럼 사용 예:
-- Sequence 컬럼에 nextval Function을 사용하여 다음 Sequence 값 입력
INSERT INTO table_name (v1, v2) values (nextval(v1), 'aaaa');
-- Sequence 컬럼에 직접 값을 입력
INSERT INTO table_name (v1, v2) values (100, 'aaaa');
-- Sequence 컬럼에 연산을 통한 값을 입력
INSERT INTO table_name (v1, v2) values (100 + 1, 'aaaa');
-- Sequence 컬럼을 포함한 Lookup 테이블에 대한 정상 Select
SELECT v1, v2 FROM table_name;
-- Sequence 컬럼에 대한 잘못된 Select (nextval 컬럼은 insert 시에만 사용 가능)
SELECT nextval(v1), v2 FROM table_name;DROP TABLE
drop_table_stmt:

drop_table_stmt ::= 'DROP TABLE' table_name지정된 테이블을 삭제한다. 단, 해당 테이블을 검색 중인 다른 세션이 존재할 경우에는 에러를 내면서 실패한다.
--예제
DROP TABLE TableName;CREATE TABLESPACE
create_tablespace_stmt:

datadisk_list:
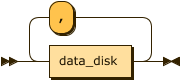
data_disk:

data_disk_property:

create_tablespace_stmt ::= 'CREATE TABLESPACE' tablespace_name 'DATADISK' datadisk_list
datadisk_list ::= data_disk ( ',' data_disk )*
data_disk ::= disk_name data_disk_property
data_disk_property ::= '(' 'DISK_PATH' '=' '"' path '"' ( ',' 'PARALLEL_IO' '=' number )? ')'-- 예제
create tablespace tbs1 datadisk disk1 (disk_path=""); -- $MACHBASE_HOME/dbs/ 에 생성
create tablespace tbs1 datadisk disk1 (disk_path="tbs1_disk1"); -- $MACHBASE_HOME/dbs/tbs1_disk1 에 생성되며 이때 tbs1_disk1폴더가 존재해야 한다.
create tablespace tbs2 datadisk disk1 (disk_path="tbs2_disk1", parallel_io = 5);
create tablespace tbs1 datadisk disk1 (disk_path="tbs1_disk1", parallel_io = 10), disk2 (disk_path="tbs1_disk2"), disk3 (disk_path="tbs1_disk3");CREATE TABLESPACE 구문은 로그 Table 또는 로그 Table의 Index가 저장될 Tablespace를 $MACHBASE_HOME/dbs/ 에 생성한다.
Tablespace는 여러 개의 Disk를 가질 수 있다. Table과 Index의 데이터를 저장하는 각각의 Partition File들이 저장될 때, Tablespace에 속한 Data Disk들에 분산되어 저장된다.
만약 2개 이상의 Disk를 사용 시 Index와 Table의 여러 File이 각 Disk에 분산 저장되고, 각각의 Device에서 Parallel 하게 IO가 수행되어 Disk 개수가 늘어날수록 Disk I/O Throughput 이 높아져 다량의 Data를 빠르게 Disk에 저장할 수 있는 이점이 있다.
또한, Table과 Index의 Tablespace를 별도로 생성하고 각각 다른 Disk를 정의할 경우, Physical Disk의 재구성 없이, Logical 하게 Table과 Index의 I/O를 분리할 수 있다.
DATA DISK
Tablespace에 속한 Disk를 정의한다. 각 Disk는 다음과 같은 속성을 가진다.
| 속성 | 설명 |
|---|---|
| data_disk_property | Disk의 속성을 지정한다. |
| disk_name | Disk 객체의 이름을 지정한다. 추후에 Alter Tablespace구문을 통해서 Disk객체의 속성을 변경할 때 사용한다. |
| disk_path | Disk의 Directory Path를 지정한다. 이 Directory는 Create 되어 있어야 한다. 상대 Path로 Path를 지정시 $MACHBASE_HOME/dbs 기준으로 PATH를 찾는다. 예를 들어 PATH=‘disk1’일 경우 Disk Path를 $MACHBASE_HOME/dbs/disk1으로 인식한다. |
| parallel_io | Disk의 IO Request를 Parallel하게 몇 개까지 허용할 지를 결정한다. (DEF: 3, MIN: 1, MAX: 128) |
DROP TABLESPACE
drop_tablespace_stmt:

drop_table_stmt ::= 'DROP TABLESPACE' tablespace_name지정된 Tablespace를 삭제한다. 하지만 Tablespace에 생성된 객체가 존재하는 경우, 삭제가 실패한다.
--예제
DROP TABLESPACE TablespaceName;CREATE INDEX
create_index_stmt:

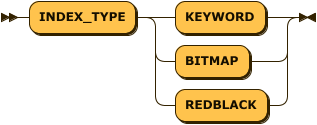
index_type:
table_space:

index_property_list:
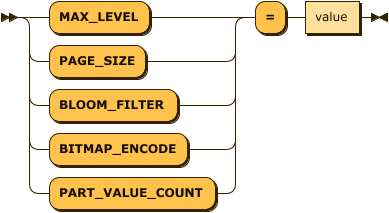
create_index_stmt ::= 'CREATE' 'INDEX' index_name 'ON' table_name '(' column_name ')' index_type? table_space? index_property_list?
index_type ::= 'INDEX_TYPE' ( 'KEYWORD' | 'BITMAP' | 'REDBLACK' )
table_space ::= 'TABLESPACE' table_space_name
index_property_list ::= ( 'MAX_LEVEL' | 'PAGE_SIZE' | 'BITMAP_ENCODE' | 'PART_VALUE_COUNT' ) '=' valueIndex Type
생성할 Index Type을 지정한다. Keyword Index가 아닌 경우 Index Type을 지정하지 않으면 Table Type에 따라서 Default Index Type으로 Index가 생성된다.
| Table Type | Default Index Type |
|---|---|
| Volatile Table | REDBLACK |
| Lookup Table | REDBLACK |
| Log Table | LSM |
KEYWORD Index
텍스트 검색을 위한 인덱스로써 로그 테이블의 varchar와 text 컬럼에만 생성 가능하며, 단일 컬럼에 대해서만 생성할 수 있다.
LSM Index
LSM(Log Structure Merge) Index로 Big Data에 저장 및 검색에 최적화된 Index이다. LSM Index들의 Partition들은 Level 별로 유지되고 하위 Level의 Partition들이 Merge되어 상위 Level로 이동한다. 그리고 상위 Level의 Partition 생성에 사용된 하위 Partition들은 삭제된다.
이러한 Index Level Partition Building은 Background Thread 에 의해서 수행된다. 상위 Level Partition은 하위 Level의 Partition 들이 Merge되어 하나의 Partition으로 생성되기 때문에 Index를 통한 검색 시 다음과 같은 장점이 존재한다.
- Key가 중복된 경우, 한 번만 저장되기 때문에 Key 저장을 위한 Disk Space가 절약된다.
- 여러 개의 Partition에 대한 Searching보다 하나의 Index Partition에 대한 검색 시 File Open 및 Close 비용이 줄어들고, 접근하는 Index Page의 개수 또한 줄어든다.
LSM Index Property
| 항목 | 설명 |
|---|---|
| MAX_LEVEL (DEFAULT = 3, MIN = 0, MAX = 3 ) | LSM Index의 최대 Level로서 현재 3이 최대값이다. 그리고 하나의 Partition의 최대 Record 건수는 2억건을 초과할 수 없다. 각 Level의 Partition 크기는 이전 Partition의 Value 개수 * 10이다. 예를 들면 MAX_LEVEL = 3, PART_VALUE_COUNT가 100,000 이면 Level 0 = 100,000, Level 1 = 1,000,0000, Level 2 = 10,000,000, Level 3 = 100,000,000 이다. 만약 마지막 Level의 Partition Size가 2억건을 초과하면 Index 생성이 실패한다. |
| PAGE_SIZE (DEFAULT = 512 * 1024, MIN = 32 * 1024,MAX = 1 * 1024 * 1024) | Index의 Key Value와 Bitmap 값이 저장되는 Page의 크기를 지정한다. Default는 512K이다. |
| BITMAP_ENCODE (DEFAULT = EQUAL, RANGE) | 인덱스의 Bitmap 타입을 설정한다. BITMAP_ENCODE=EQUAL(기본값)의 경우 키값과 같은 값에 대한 bitmap을 생성하고 BITMAP=RANGE인 경우 키값의 range에 따른 bitmap을 생성한다. 질의 조건으로 = 을 주로 사용하는 경우 BITMAP_ENCODE=EQUAL로, 특정 범위값을 질의 조건으로 주로 사용하는 경우 BITMAP_ENCODE=RANGE로 설정하는 편이 좋다. BITMAP=RANGE인 경우 생성 비용은 EQUAL에 비해서 약간 증가한다. |
BITMAP 인덱스
데이터 분석을 위한 인덱스로서, 로그 테이블에만 생성 가능하다. 그리고 varchar, text, binary를 제외한 모든 컬럼에 생성 가능하며, 단일 컬럼에 대해서만 생성할 수 있다.
RED-BLACK 인덱스
실시간 데이터 검색을 위한 메모리 인덱스로서, Volatile/Lookup 테이블에만 생성 가능하다. 그리고 이 테이블의 모든 컬럼에 생성 가능하며 단일 컬럼에 대해서만 생성할 수 있다.
Index Property
LSM Index 에서 적용할 수 있는 Property 는 다음과 같다.
PART_VALUE_COUNT
Index의 Partition에 저장되는 Row 개수를 나타낸다.
--예제
-- c1 컬럼에 index가 적용되었다.
CREATE INDEX index1 on table1 ( c1 )
-- varchar type의 var_column에 keyword index가 적용되고 page_size의 단위는 100000가 되었다.
CREATE INDEX index2 on table1 (var_column) INDEX_TYPE KEYWORD PAGE_SIZE=100000;DROP INDEX
drop_index_stmt:

drop_index_stmt ::= 'DROP INDEX' index_name지정된 인덱스를 삭제한다. 단, 해당 테이블을 검색 중인 다른 세션이 존재할 경우에는 에러를 내면서 실패한다.
-- 예제
DROP INDEX IndexName;ALTER TABLE
ALTER TABLE 구문은 지정된 테이블의 스키마 정보를 변경시키기 위한 용도로 사용되며 Log Table 만 사용 가능하다.
ALTER TABLE SET
이 구문은 Table의 Property를 변경하는 구문이다. 현재 동적으로 변경 가능한 Property는 없다.
ALTER TABLE ADD COLUMN
alter_table_add_stmt:

alter_table_add_stmt ::= 'ALTER TABLE' table_name 'ADD COLUMN' '(' column_name column_type ( 'DEFAULT' value )? ')'이 구문은 테이블에 특정 컬럼을 실시간으로 추가하는 기능이다. 컬럼의 이름과 타입을 추가하고, DEFAULT 구문을 통해 기본 데이터 값을 설정할 수 있다.
-- 예제-1
alter table atest2 add column (id4 float);
-- 예제-2
alter table atest2 add column (id6 double default 5);
alter table atest2 add column (id7 ipv4 default '192.168.0.1');
alter table atest2 add column (id8 varchar(4) default 'hello');ALTER TABLE DROP COLUMN
alter_table_drop_stmt:

alter_table_drop_stmt ::= 'ALTER TABLE' table_name 'DROP COLUMN' '(' column_name ')'이 구문은 테이블에 특정 컬럼을 실시간으로 삭제하는 기능이다.
-- 예제
alter table atest2 drop column (id4);
alter table atest2 drop column (id8);ALTER TABLE RENAME COLUMN
alter_table_column_rename_stmt:

alter_table_column_rename_stmt ::= 'ALTER TABLE' table_name 'RENAME COLUMN' old_column_name 'TO' new_column_name이 구문은 테이블의 특정 컬럼명을 변경하는 기능이다.
-- 예제
alter table atest2 rename column id7 to id7_rename;ALTER TABLE MODIFY COLUMN
alter_table_modify_stmt:
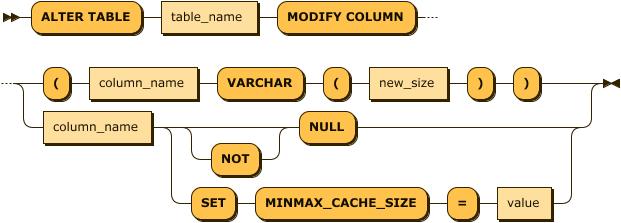
alter_table_modify_stmt ::= 'ALTER TABLE' table_name 'MODIFY COLUMN' ( '(' column_name 'VARCHAR' '(' new_size ')' ')' | column_name ( 'NOT'? 'NULL' | 'SET' 'MINMAX_CACHE_SIZE' '=' value ) )이 구문은 테이블의 특정 컬럼의 속성을 변경하는 것이다. 현재는 VARCHAR 타입의 컬럼 길이와 그외 타입에 대한 MINMAX CACHE 속성과 NOT NULL 제약조건을 수정하는 것이 가능하다.
VARCHAR SIZE
이 구문은 VARCHAR 타입의 컬럼 길이만 변경하는 것을 지원한다. 이 동작은 기존의 데이터를 보존하기 위해 그 길이가 줄어들 수는 없으며, 언제나 증가해야 한다.
ALTER TABLE table_name MODIFY COLUMN (column_name VARCHAR(new_size));-- 예제 : TABLE 이 이렇게 만들어졌다고 가정하자.
-- create table atest5 (id integer, name varchar(5), id3 double, id4 float);
-- 에러 발생: 다른 타입으로 변경할 수 없음.
alter table atest5 modify column (id varchar(10));
-- 에러 발생: VARCHAR 길이를 더 작게 할 수 없음.
alter table atest5 modify column (name varchar(3));
-- 에러 발생: VARCHAR의 최대 크기 32767 이상 넘을 수 없음.
alter table atest5 modify column (name varchar(32768));
-- 성공
alter table atest5 modify column (name varchar(128));MINMAX_CACHE_SIZE
이 구문은 특정 컬럼에 대해 MINMAX_CACHE_SIZE를 변경한다.
ALTER TABLE table_name MODIFY COLUMN column_name SET MINMAX_CACHE_SIZE=value;-- 예제 : TABLE 이 이렇게 만들어졌다고 가정하자.
create table atest9 (id integer, name varchar(100));
-- 에러: VARCHAR에는 적용 안됨.
alter table atest9 modify column name set minmax_cache_size=0;
[ERR-02139 : MINMAX CACHE is not allowed for VARCHAR column(NAME).]
-- 변경 성공
alter table atest9 modify column id set minmax_cache_size=10240;NOT NULL
컬럼에 NOT NULL 제약 조건을 추가한다. NOT NULL 제약 조건을 추가할 경우 NULL값이 있는 컬럼에 대해서는 DDL연산이 실패한다.
만약 컬럼에 NULL값을 허용하고 싶은 경우에는 다음 절의 MODIFY COLUMN NULL 명령어를 이용한다.
ALTER TABLE table_name MODIFY COLUMN column_name NOT NULL;-- t1.c1에 NOT NULL 제약조건을 추가한다.
alter table t1 modify column c1 not null;NULL
NOT NULL 제약조건을 해제한다. LSM 인덱스의 min_max 캐시로 인한 성능 향상을 얻을 수 없다. NULL 값의 입력이 가능해 진다.
ALTER TABLE table_name MODIFY COLUMN column_name NULL;-- t1.c1에 NOT NULL 제약조건을 해제한다.
alter table t1 modify column c1 null;ALTER TABLE RENAME TO
alter_table_rename_stmt:

alter_table_rename_stmt ::= 'ALTER TABLE' table_name 'RENAME TO' new_name테이블의 이름을 변경한다.
메타 테이블들은 이름을 변경할 수 없고, 변경될 이름에 $문자는 사용할 수 없다. 테이블 이름 변경은 Log 테이블에 대해서만 가능하다.
-- worker 테이블의 이름을 employee로 변경한다.
ALTER TABLE worker RENAME TO employee;ALTER TABLE ADD RETENTION
alter_table_add_retention_stmt:
alter_table_add_retention_stmt ::= 'ALTER TABLE' table_name 'ADD RETENTION' policy_name
ALTER TABLE tag ADD RETENTION policy_1d_1h;ALTER TABLE DROP RETENTION
alter_table_drop_retention_stmt:
alter_table_drop_retention_stmt ::= 'ALTER TABLE' table_name 'DROP RETENTION'
ALTER TABLE tag DROP RETENTION;ALTER TABLESPACE
ALTER TABLESPACE 구문은 지정된 Tablespace에 관련된 정보를 변경하는데 사용된다.
ALTER TABLESPACE MODIFY DATADISK
이 구문은 Tablespace의 DATADISK의 속성을 변경하는데 사용된다.
alter_tablespace_stmt:

alter_tablespace_stmt ::= 'ALTER TABLESPACE' table_name 'MODIFY DATADISK' disk_name 'SET' 'PARALLEL_IO' '=' value-- 예제
ALTER TABLESPACE tbs1 MODIFY DATADISK disk1 SET PARALLEL_IO = 10;TRUNCATE TABLE
truncate_table_stmt:

truncate_table_stmt ::= 'TRUNCATE TABLE' table_name-- ctest 테이블의 모든 데이터를 삭제한다.
Mach> truncate table ctest;
Truncated successfully.지정된 테이블에 존재하는 모든 데이터를 삭제한다. 단, 해당 테이블을 검색 중인 다른 세션이 존재할 경우에는 에러를 내면서 실패한다.
CREATE ROLLUP
create_rollup_stmt:
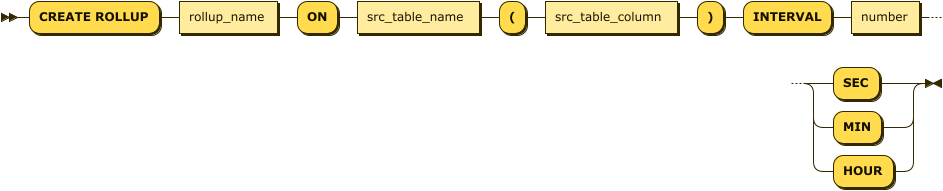
create_rollup_stmt ::= 'CREATE ROLLUP' rollup_name 'ON' src_table_name '('src_table_column')' 'INTERVAL' number ('SEC' | 'MIN' | 'HOUR')-- tag table의 value 칼럼을 대상으로 rollup을 생성한다.
Mach> CREATE ROLLUP _rollup_tag_value_sec ON tag(value) INTERVAL 1 SEC;
Executed successfullyDROP ROLLUP
drop_rollup_stmt:

drop_rollup_stmt ::= 'DROP ROLLUP' rollup_name-- rollup을 삭제한다.
Mach> DROP ROLLUP _rollup_tag_value_sec;
Executed successfullyCREATE RETENTION
create_retention_stmt:
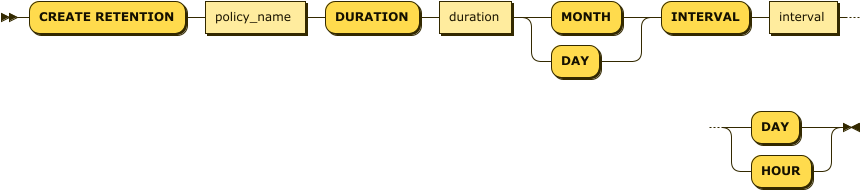
create_retention_stmt ::= 'CREATE RETENTION' policy_name 'DURATION' duration ( 'MONTH' | 'DAY' ) 'INTERVAL' interval ( 'DAY' | 'HOUR' )-- retention policy를 생성한다.
Mach> CREATE RETENTION policy_1d_1h DURATION 1 DAY INTERVAL 1 HOUR;
Executed successfullyDROP RETENTION
drop_retention_stmt:

drop_retention_stmt ::= 'DROP RETENTION' policy_name-- retention policy를 삭제한다.
Mach> DROP RETENTION policy_1d_1h;
Executed successfully