DML
INSERT
insert_stmt:
insert_column_list:
value_list:
set_list:
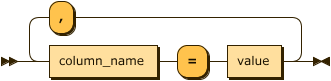
insert_stmt ::= 'INSERT INTO' table_name ( '(' insert_column_list ')' )? 'METADATA'? 'VALUES' '(' value_list ')' ( 'ON DUPLICATE KEY UPDATE' ( 'SET' set_list )? )?
insert_column_list ::= column_name ( ',' column_name )*
value_list ::= value ( ',' value )*
set_list ::= column_name '=' value ( ',' column_name '=' value )*create table test (number int,name varchar(20));
Created successfully.
insert into test values (1,"test");
1 row(s) inserted.
insert into test(name,number) values ("test",2);
1 row(s) inserted.특정 테이블에 값을 입력하는 구문이다. 한 가지 특이한 점은 Column_List에서 지정되지 않은 컬럼에는 모두 NULL 값으로 채워진다는 것이다. 이는 입력의 편의성과 저장 공간의 효율화를 위해 채택된 로그 파일의 특성을 고려한 정책이다.
METADATA는 tag table에만 사용이 가능하다.
INSERT ON DUPLICATE KEY UPDATE
마크베이스는, 흔히 알려진 UPSERT 기능과 유사한 구문을 지원한다.
기본 키가 지정된 Lookup/Volatile 테이블에 값을 입력할 때 사용할 수 있는 특수 구문으로, 기본 키 값이 중복되는 데이터가 이미 테이블에 존재하는 경우에는 기존 데이터의 값이 변경된다. 물론, 키 값이 중복되는 데이터가 존재하지 않는 경우에는 새로운 데이터로 삽입된다.
이 구문을 사용하기 위해서, 휘발성 테이블에 기본 키가 지정되어 있어야 한다.
삽입되는 데이터의 컬럼 값과 갱신되는 데이터의 컬럼 값을 다르게 하고자 하는 경우, 또는 삽입되는 데이터의 컬럼 값이 아닌 다른 컬럼 값을 갱신하고자 하는 경우에는 SET 절을 추가로 입력할 수 있다.
- SET 절에는 ‘컬럼=값’으로 구성되며, 각각을 콤마로 구분해야 한다.
- SET 절에서 기본 키 값을 변경해서는 안 된다.
INSERT SELECT
insert_select_stmt:

insert_select_stmt ::= 'INSERT INTO' table_name ( '(' insert_column_list ')' )? select_stmt특정 table에 대해서 SELECT 문의 수행 결과를 삽입하는 문장이다. 기본적으로는 다른 DBMS와 유사하지만 다음의 차이점이 있다.
- _ARRIVAL_TIME 컬럼 값은 select 및 INSERT 컬럼 리스트에서 지정되지 않으면 INSERT SELECT 문이 수행되는 시점의 시간 값으로 입력된다.
- VARCHAR 타입의 컬럼에 대해서 삽입되는 입력값이 컬럼의 최대 길이보다 큰 경우, 오류를 발생시키지 않고 해당 컬럼의 최대 길이만큼 잘라서 입력된다.
- 형 변환이 가능한 경우(숫자형->숫자형)에는 입력되는 컬럼 값에 맞게 삽입된다.
- 수행 도중 오류가 발생한 경우 ROLLBACK되지 않는다.
- _ARRIVAL_TIME 컬럼의 값을 지정하여 삽입하는 경우, 새로 입력되는 값이 기존의 값보다 이전 시간을 갖고 있으면 입력되지 않는다.
create table t1 (i1 integer, i2 varchar(60), i3 varchar(5));
Created successfully.
insert into t1 values (1, 'a', 'ddd' );
1 row(s) inserted.
insert into t1 values (2, 'kkkkkkkkkkkkkkkkkkkkk', 'c');
1 row(s) inserted.
insert into t1 select * from t1;
2 row(s) inserted.
create table t2 (i1 integer, i2 varchar(60), i3 varchar(5));
insert into t2 (_arrival_time, i1, i2, i3) select _arrival_time, * from t1;
4 row(s) inserted.UPDATE
- 5.5 부터 제공되는 기능입니다.
update_stmt:

update_expr_list:

update_expr:

update_stmt ::= 'UPDATE' table_name ( 'METADATA' )? 'SET' update_expr_list 'WHERE' primary_key_column '=' value
update_expr_list ::= update_expr ( ',' update_expr)*
update_expr ::= column '=' valueINSERT ON DUPLICATE KEY UPDATE 를 통한 UPSERT 가 아닌, UPDATE 구문도 제공된다.
역시, 기본 키 (Primary Key) 가 지정된 Lookup/Volatile 테이블에 값을 입력할 때 사용할 수 있다. WHERE 절에는 기본 키의 일치 조건식을 작성해야 한다.
UPDATE METADATA
TAGDATA 테이블에 한해서, 메타데이터를 업데이트 하고자 할 때 사용한다.
UPDATE TAG METADATA SET ...- TAGDATA 테이블의 메타데이터는 INSERT ON DUPLICATE KEY UPDATE 를 통해 입력/수정할 수 없다.
DELETE
delete_stmt:
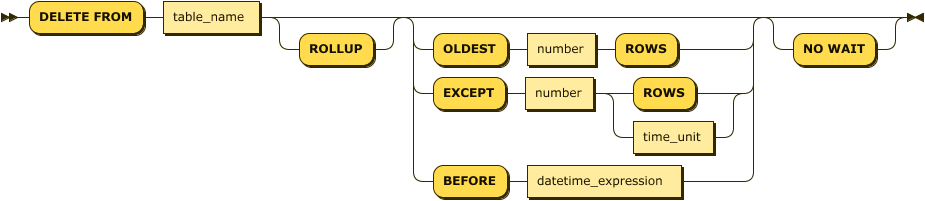
time_unit:
delete_stmt ::= 'DELETE FROM' table_name ( 'OLDEST' number 'ROWS' | 'EXCEPT' number ( 'ROWS' | time_unit ) | 'BEFORE' datetime_expression )? 'NO WAIT'?
time_unit ::= 'DURATION' number time_unit ( ( 'BEFORE' | 'AFTER' ) number time_unit )?마크베이스에서의 DELETE BEFORE 구문은 로그 테이블, Tag 테이블, Rollup table에 대해서 수행 가능하다. 중간의 임의 위치에 있는 데이터를 삭제할 수 없으며, 임의의 위치부터 연속적으로 마지막(가장 오래된 로그) 레코드까지 지울 수 있도록 구현되었다.
이는 로그 데이터의 특성을 살린 정책으로서 한번 입력되면 수정이 없고, 공간 확보를 위해 파일을 삭제하는 행위를 DB 형식으로 표현한 것이다.
DURATION, OLDEST, EXCEPT 구문은 TAG 및 Rollup 테이블에 대해서는 사용할 수 없다.
-- 모두 삭제하라.
DELETE FROM devices;
-- 가장 오래된 마지막 N건을 삭제하라.
DELETE FROM devices OLDEST N ROWS;
-- 최근 N건을 제외하고 모두 삭제하라.
DELETE FROM devices EXCEPT N ROWS;
-- 지금부터 N일치를 남기고 모두 삭제하라.
DELETE FROM devices EXCEPT N DAY;
-- 2014년 6월 1일 이전의 데이터를 모두 삭제하라.
DELETE FROM devices BEFORE TO_DATE('2014-06-01', 'YYYY-MM-DD');
-- tag 데이터의 시간 기준 삭제
DELETE FROM tag BEFORE TO_DATE('2014-06-01', 'YYYY-MM-DD');
-- tag rollup 데이터의 시간 기준 삭제
DELETE FROM tag ROLLUP BEFORE TO_DATE('2014-06-01', 'YYYY-MM-DD');DELETE WHERE
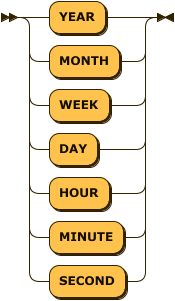
delete_where_stmt:

delete_where_stmt ::= 'DELETE FROM' table_name 'WHERE' column_name '=' valuecreate volatile table t1 (i1 int primary key, i2 int);
Created successfully.
insert into t1 values (2,2);
1 row(s) inserted.
delete from t1 where i1 = 2;
1 row(s) deleted.휘발성 테이블에 대해서만 수행 가능한 구문으로, WHERE 절에 작성된 조건에 일치하는 레코드만 삭제할 수 있다.
- 기본 키가 지정된 휘발성 테이블에 대해서만 수행 가능하다.
- WHERE 절에는 (기본 키 컬럼) = (값) 의 조건만 허용되며, 다른 조건과 함께 작성할 수 없다.
- 기본 키 컬럼이 아닌 다른 컬럼을 조건에 사용할 수 없다.
delete_from_tag_where_stmt:
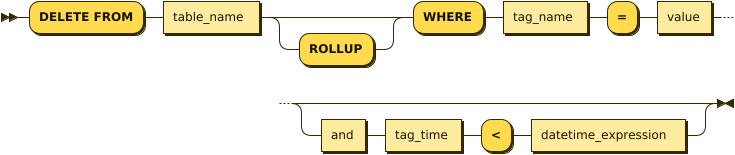
delete_from_tag_where_stmt ::= 'DELETE FROM' table_name 'ROLLUP'? 'WHERE' tag_name '=' value ( and tag_time '<' datetime_expression )?Tag 테이블 및 Rollup 테이블은 아래와 같이 두가지 방식의 삭제 구문이 지원된다.
- Tag name 기준 삭제
- Tag name과 Tag time 기준 삭제
-- tag name 기준 삭제
DELETE FROM tag WHERE tag_name = 'my_tag_2021'
-- tag name 와 tag time 기준 삭제
DELETE FROM tag WHERE tag_name = 'my_tag_2021' AND tag_time < TO_DATE('2021-07-01', 'YYYY-MM-DD');
-- tag name 기준 rollup 삭제
DELETE FROM tag ROLLUP WHERE tag_name = 'my_tag_2021'
-- tag name 와 tag time 기준 rollup 삭제
DELETE FROM tag ROLLUP WHERE tag_name = 'my_tag_2021' AND tag_time < TO_DATE('2021-07-01', 'YYYY-MM-DD');- 삭제 쿼리가 실행된 후에, 삭제된 row가 저장공간에서 물리적으로 삭제되기 까지 걸리는 시간은, DBMS의 동작상황에 따라서 다를 수 있다.
LOAD DATA INFILE
load_data_infile_stmt:
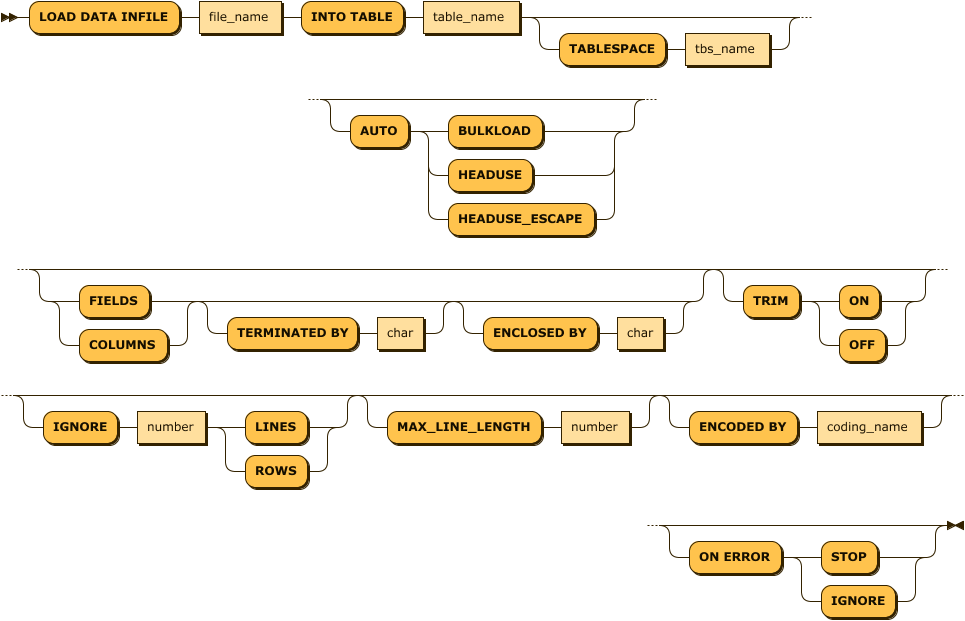
load_data_infile_stmt: 'LOAD DATA INFILE' file_name 'INTO TABLE' table_name ( 'TABLESPACE' tbs_name )? ( 'AUTO' ( 'BULKLOAD' | 'HEADUSE' | 'HEADUSE_ESCAPE' ) )? ( ( 'FIELDS' | 'COLUMNS' ) ( 'TERMINATED BY' char )? ( 'ENCLOSED BY' char )? )? ( 'TRIM' ( 'ON' | 'OFF' ) )? ( 'IGNORE' number ( 'LINES' | 'ROWS' ) )? ( 'MAX_LINE_LENGTH' number )? ( 'ENCODED BY' coding_name )? ( 'ON ERROR' ( 'STOP' | 'IGNORE' ) )?CSV 포맷의 데이터 파일을 서버에서 직접 읽어서, 옵션에 따라 서버에서 직접 테이블 및 컬럼들을 생성하여 이를 입력하는 기능이다.
각 옵션에 대해서 설명하면 다음과 같다.
| 옵션 | 설명 |
|---|---|
| AUTO mode_string mode_string = (BULKLOAD | HEADUSE | HEADUSE_ESCAPE) | 해당 테이블을 생성하고 컬럼 타입(자동 생성시 varchar type) 및 컬럼명을 자동으로 생성한다. BULKLOAD: 데이터 한 개의 row를 하나의 컬럼으로 입력한다. 컬럼으로 구분할 수 없는 데이터에 대해서 사용한다. HEADUSE: 데이터 파일의 첫 번째 라인에 기술되어 있는 컬럼 명을 테이블의 컬럼명으로 사용하고, 그 라인에 기술된 수 만큼의 컬럼을 생성한다. HEADUSE_ESCAPE: HEADUSE 옵션과 유사하지만, 컬럼명이 DB의 예약어와 같을 경우 발생할 수 있는 오류를 회피하기 위해 컬럼명의 앞뒤로 ‘’ 문자를 덧붙이고, 컬럼명에 특수문자가 존재하면 그 문자를 ‘’ 문자로 변경한다. |
(FIELDS|COLUMNS) TERMINATED BY ’term_char’ ESCAPED BY ’escape_char’ | 데이터 라인을 파싱하기 위한 구분 문자(term_char)와 이스케이프 문자(escape_char)를 지정한다. 일반적인 CSV 파일의 경우 구분 문자는 , 이며 이스케이프 문자는 ‘이다. |
| ENCODED BY coding_name coding_name = { UTF8(default) | MS949 | KSC5601 | EUCJP | SHIFTJIS | BIG5 | GB231280 } | 데이터 파일의 인코딩 옵션을 지정한다. 기본 값은 UTF-8이다. |
| TRIM (ON | OFF) | 컬럼의 빈 공간을 제거하거나 유지한다. 기본값은 ON이다. |
| IGNORE number (LINES | ROWS) | 숫자로 지정된 라인 또는 행 만큼의 데이터를 무시한다. CSV 포맷 파일의 헤더 등을 무시하거나 VCF 헤더를 무시하기 위해서 사용한다. |
| ON ERROR (STOP | IGNORE) | 입력 도중 에러가 발생할 경우 수행할 동작을 지정한다. STOP인 경우 입력을 중단하고 IGNORE인 경우 에러가 발생한 라인을 건너뛰고 계속 입력한다. 기본값은 IGNORE이다. |
-- default field delimiter(,) field encloser (") 를 사용하여 데이터를 입력한다.
LOAD DATA INFILE '/tmp/aaa.csv' INTO TABLE Sample_data ;
-- 하나의 컬럼을 갖는 NEWTABLE을 생성해서 한 라인을 한 컬럼으로 입력한다.
LOAD DATA INFILE '/tmp/bbb.csv' INTO TABLE NEWTABLE AUTO BULKLOAD;
-- csv의 첫번째 라인을 컬럼 정보로 이용하여 NEWTABLE을 생성하고, 이를 그 테이블에 입력한다.
LOAD DATA INFILE '/tmp/bbb.csv' INTO TABLE NEWTABLE AUTO HEADUSE;
-- 첫번째 라인은 무시하고 필드 구분자는 ; enclosing 문자는 ' 로 지정해서 입력한다.
LOAD DATA INFILE '/tmp/ccc.csv' INTO TABLE Sample_data FIELDS TERMINATED BY ';' ENCLOSED BY '\'' IGNORE 1 LINES ON ERROR IGNORE;- AUTO 옵션을 사용하지 않는 경우 테이블의 모든 컬럼은 VARCHAR 또는 TEXT 타입으로 생성해야 한다.