Python 클라이언트
조회
GET CSV
import requests
params = {"q":"select * from example", "format":"csv", "heading":"false"}
response = requests.get("http://127.0.0.1:5654/db/query", params)
print(response.text)쓰기
POST CSV
import requests
csvdata = """temperature,1677033057000000000,21.1
humidity,1677033057000000000,0.53
"""
response = requests.post(
"http://127.0.0.1:5654/db/write/example?heading=false",
data=csvdata,
headers={'Content-Type': 'text/csv'})
print(response.json())예시 - matplotlib
📌
테스트 데이터를 입력하려면 셸 스크립트로 웨이브 쓰기에 있는 아래 명령을 사용하십시오.
sh gen_wave.sh | machbase-neo shell import --timeformat=s EXAMPLEPython 코드
import requests
import json
import datetime
import matplotlib.pyplot as plt
import numpy as np
url = "http://127.0.0.1:5654/db/query"
querystring = {"q":"select * from example order by time limit 200"}
response = requests.request("GET", url, params=querystring)
data = json.loads(response.text)
sinTs, sinSeries, cosTs, cosSeries = [], [], [], []
for row in data["data"]["rows"]:
ts = datetime.datetime.fromtimestamp(row[1]/1000000000)
if row[0] == 'wave.cos':
cosTs.append(ts)
cosSeries.append(row[2])
else:
sinTs.append(ts)
sinSeries.append(row[2])
plt.plot(sinTs, sinSeries, label="sin")
plt.plot(cosTs, cosSeries, label="cos")
plt.title("튜토리얼 웨이브")
plt.legend()
plt.show()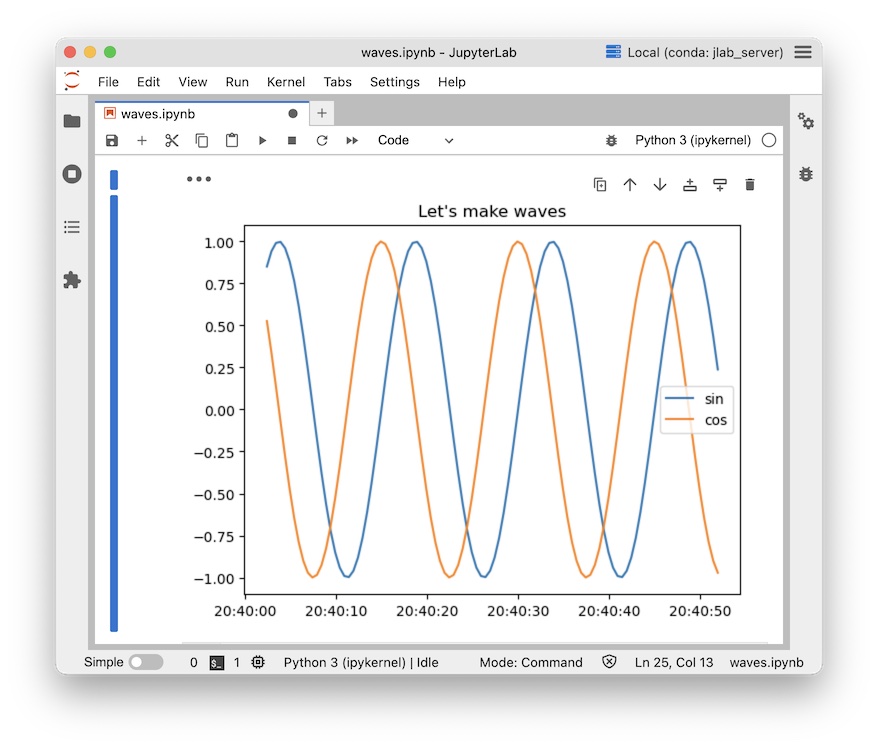
예시 - pandas
테이블에서 데이터프레임 로드
- machbase-neo HTTP API를 사용해 pandas 데이터프레임을 불러옵니다.
from urllib import parse
import pandas as pd
query_param = parse.urlencode({
"q": "select * from example order by time limit 500",
"format": "csv",
"timeformat": "s",
})
df = pd.read_csv(f"http://127.0.0.1:5654/db/query?{query_param}")
df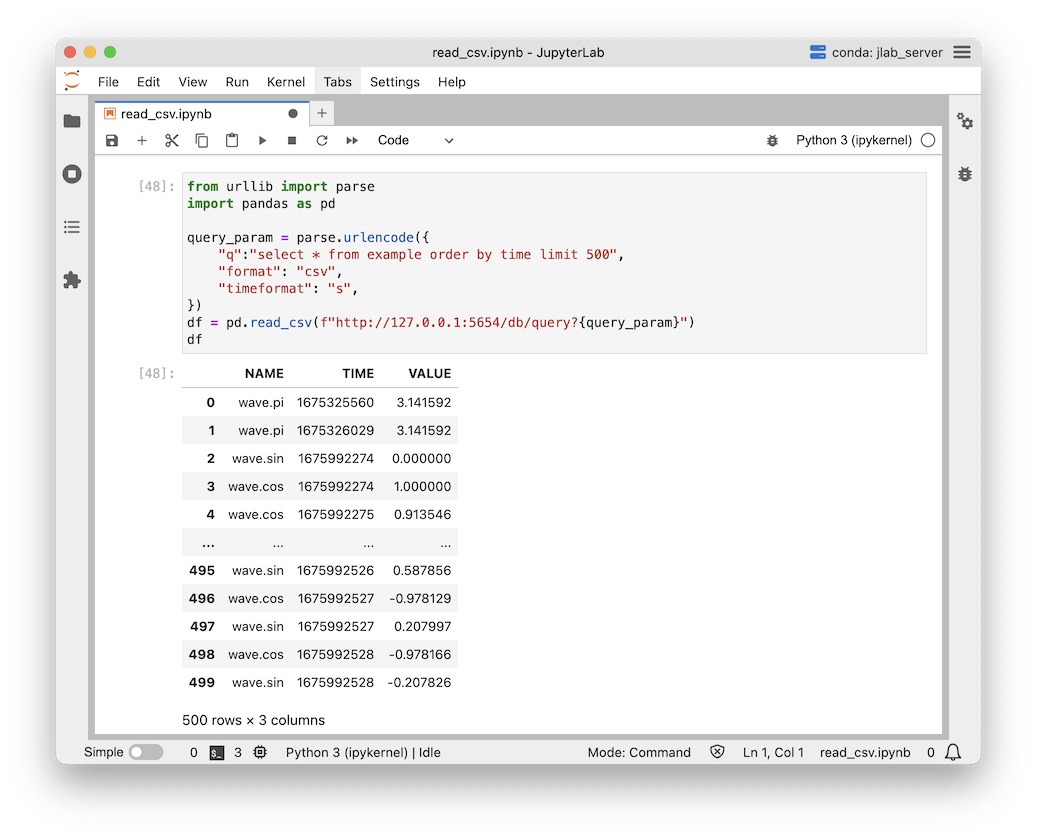
데이터프레임을 테이블에 쓰기
- machbase-neo HTTP API를 통해 pandas 데이터프레임을 태그 테이블에 저장합니다.
import io, requests
stream = io.StringIO()
df.to_csv(stream, encoding='utf-8', header=False, index=False)
stream.seek(0)
file_upload_resp = requests.post(
"http://127.0.0.1:5654/db/write/example?timeformat=s&method=append",
headers={'Content-type':'text/csv'},
data=stream )
print(file_upload_resp.json()){'success': True, 'reason': 'success, 500 record(s) appended', 'elapse': '2.288791ms'}CSV 로드
- pandas와 urllib를 임포트합니다.
from urllib import parse
import pandas as pd"format": "csv" 옵션으로 쿼리 URL을 만든 뒤 read_csv를 호출합니다.
시간 데이터의 정밀도는 timeformat으로 지정하며 s, ms, us, ns(기본값)를 사용할 수 있습니다.
query_param = parse.urlencode({
"q":"select * from example order by time limit 500",
"format": "csv",
"timeformat": "s",
})
df = pd.read_csv(f"http://127.0.0.1:5654/db/query?{query_param}")
df압축 CSV 로드
- HTTP API에서 gzip으로 압축된 CSV를 읽습니다.
from urllib import parse
import pandas as pd
import requests
import ioquery_param = parse.urlencode({
"q":"select * from example order by time desc limit 1000",
"format": "csv",
"timeformat": "s",
"compress": "gzip",
})
response = requests.get(f"http://127.0.0.1:5654/db/query?{query_param}", timeout=30, stream=True)
df = pd.read_csv(io.BytesIO(response.content))
df최근 업데이트