MAP
MAP 함수는 데이터를 원하는 형태로 가공할 때 사용하는 핵심 도구입니다.
TAKE()
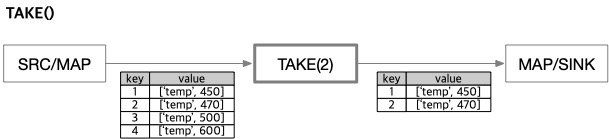
구문: TAKE( [offset,] n )
스트림에서 앞쪽 n개의 레코드를 가져온 뒤 처리를 종료합니다.
offsetnumber: 선택 값으로, 지정하면 해당 위치부터 레코드를 가져옵니다(생략 시 기본값 0). Since v8.0.6nnumber: 가져올 레코드 수입니다.
| |
TAG0,1628694000000000000,10
TAG0,1628780400000000000,11DROP()
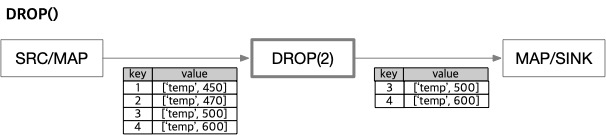
구문: DROP( [offset,] n )
앞쪽 n개의 레코드를 건너뛰고 제거합니다.
offsetnumber: 선택 값으로, 지정된 위치부터 레코드를 삭제합니다(생략 시 기본값 0). Since v8.0.6nnumber: 삭제할 레코드 수입니다.
| |
TAG0,1628953200000000000,13
TAG0,1629039600000000000,14
TAG0,1629126000000000000,15FILTER()

구문: FILTER( condition )
들어오는 레코드에 조건식을 적용해 condition이 참일 때만 다음 단계로 전달합니다.
예를 들어 입력 레코드가 {key: k1, value[v1, v2]}일 때 FILTER(count(V) > 2)를 적용하면 해당 레코드는 제거됩니다. 반대로 FILTER(count(V) >= 2)라면 레코드가 다음 함수로 전달됩니다.
| |
TAG0,1628694000000000000,10
TAG0,1628780400000000000,11FILTER_CHANGED()
구문: FILTER_CHANGED( value [, retain(time, duration)] [, useFirstWithLast()] )
Since v8.0.15
retain(time, duration)useFirstWithLast(boolean)
이전 레코드와 비교해 value가 변경된 경우에만 레코드를 통과시킵니다.
첫 번째 레코드는 항상 전달되므로, 필요하다면 FILTER_CHANGED() 뒤에 DROP(1)을 추가해 첫 번째 레코드를 제거하십시오.
retain() 옵션을 지정하면 time 값을 기준으로 주어진 기간 동안 변경된 value를 유지하는 레코드가 전달됩니다.
| |
A,1692329338,1
B,1692329340,3
C,1692329346,9
D,1692329347,9.1SET()
구문: SET(name, expression)
Since v8.0.12
namekeyword: 변수 이름expressionexpression: 변수에 할당할 값
SET은 레코드 범위에서 사용할 변수를 정의합니다. 예를 들어 SET(var, 10)으로 변수를 선언하면 이후 $var로 참조할 수 있습니다. 변수는 값 배열에 포함되지 않으므로 최종 SINK 결과에는 나타나지 않습니다.
| |
0,1
0.5,6
1,11GROUP()
구문: GROUP( [lazy(boolean),] by [, aggregators...] )
Since v8.0.7
lazy(boolean): 기본값false일 때는 이전 레코드와by()값이 달라지는 즉시 집계 결과를 출력합니다.true로 지정하면 입력 스트림이 끝날 때까지 데이터를 모은 뒤 한꺼번에 결과를 반환합니다.by(value [, label]): 그룹을 나눌 기준 값입니다.aggregatorsarray of aggregator: 사용할 집계 함수 목록입니다.
자세한 집계 함수 안내는 GROUP() 문서를 참고해 주십시오.
PUSHVALUE()
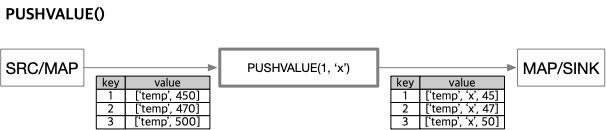
구문: PUSHVALUE( idx, value [, name] )
Since v8.0.5
idxnumber: 새 값을 삽입할 위치(0부터 시작)valueexpression: 삽입할 값namestring: 컬럼 이름(기본값은'column')
현재 값 배열에 새 컬럼을 삽입합니다.
| |
0.0,0
0.5,5
1.0,10POPVALUE()
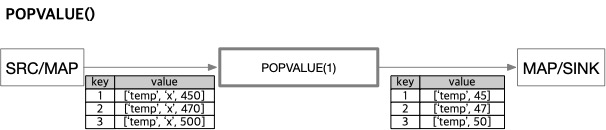
구문: POPVALUE( idx [, idx2, idx3, ...] )
Since v8.0.5
idxnumber: 제거할 컬럼 인덱스 목록입니다.
지정한 인덱스에 해당하는 컬럼을 값 배열에서 제거합니다.
| |
0
5
10MAPVALUE()
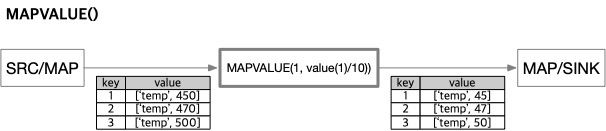
구문: MAPVALUE( idx, newValue [, newName] )
idxnumber: 값 튜플의 인덱스(0부터 시작)newValueexpression: 대체할 값newNamestring: 새로운 컬럼 이름
MAPVALUE()는 지정한 인덱스의 값을 다른 값으로 치환합니다. 예를 들어 MAPVALUE(0, value(0)*10)은 첫 번째 값을 10배 한 값으로 교체합니다.
idx가 범위를 벗어나면 PUSHVALUE()처럼 동작해 새 컬럼을 추가합니다. 예를 들어 MAPVALUE(-1, value(1)+'_suffix')는 두 번째 값에 _suffix를 이어 붙인 문자열 컬럼을 추가합니다.
| |
0
5
10아래는 MAPVALUE로 수학 연산을 적용하는 예시입니다.
| |
MAP_DIFF()
구문: MAP_DIFF( idx, value [, newName] )
Since v8.0.8
idxnumber: 값 튜플의 인덱스(0부터 시작)valuenumber: 기준이 될 값newNamestring: 새로운 컬럼 이름
MAP_DIFF()는 지정한 위치의 값을 현재 값과 이전 값의 차이(current - previous)로 교체합니다.
| |
VALUE,DIFF
-0.693,NULL
-0.251,0.442
0.054,0.305
0.288,0.234
0.477,0.189
0.636,0.159
0.773,0.137
0.894,0.121
1.001,0.108
1.099,0.097MAP_ABSDIFF()
구문: MAP_ABSDIFF( idx, value [, label] )
Since v8.0.8
idxnumber Index of the value tuple. (0 based)valuenumberlabelstring change column’s label with given string
MAP_ABSDIFF()는 현재 값과 이전 값의 절대 차이 abs(current - previous)로 값을 교체합니다.
MAP_NONEGDIFF()
구문: MAP_NONEGDIFF( idx, value [, label] )
Since v8.0.8
idxnumber Index of the value tuple. (0 based)valuenumberlabelstring change column’s label with given string
MAP_NONEGDIFF()는 현재 값과 이전 값의 차이(current - previous)로 값을 교체하며, 결과가 0보다 작으면 0을 반환합니다.
MAP_AVG()
구문: MAP_AVG(idx, value [, label] )
Since v8.0.15
idxnumber Index of the value tuple. (0 based)valuenumberlabelstring change column’s label with given string
MAP_AVG는 지정된 위치의 값을 평균 필터로 계산한 결과로 교체합니다.
데이터 개수를 $k$라고 하면
Let $\alpha = \frac{1}{k}$
$\overline{x_k} = (1 - \alpha) \overline{x_{k-1}} + \alpha x_k$
| |
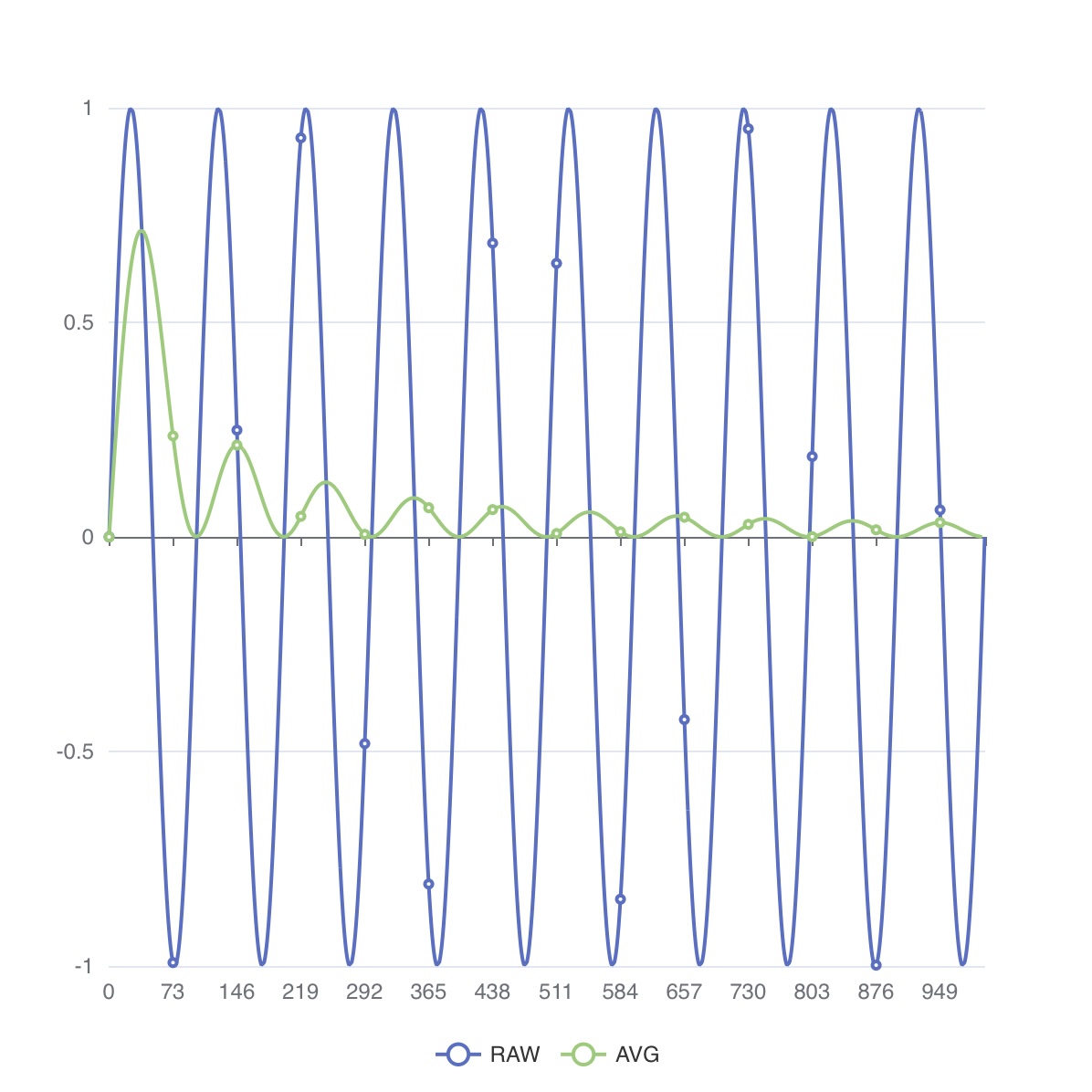
MAP_MOVAVG()
구문: MAP_MOVAVG(idx, value, window [, label] )
Since v8.0.8
idxnumber Index of the value tuple. (0 based)valuenumberwindownumber specifies how many records it accumulates.labelstring change column’s label with given string
MAP_MOVAVG는 지정된 위치의 값을 윈도 크기만큼의 이동 평균으로 교체합니다.
윈도 크기만큼 값이 채워지지 않으면 사용 가능한 값들의 합을 개수로 나눈 값을 사용합니다.
최근 window 구간에 입력이 모두 NULL(또는 숫자가 아님)이라면 결과도 NULL이 됩니다.
일부 값만 NULL일 경우, NULL을 제외한 값으로 평균을 계산합니다.
| |
- 5행: 노이즈가 섞인 신호 값을 생성합니다.
- 6행: 윈도 크기 10으로 이동 평균을 계산합니다.
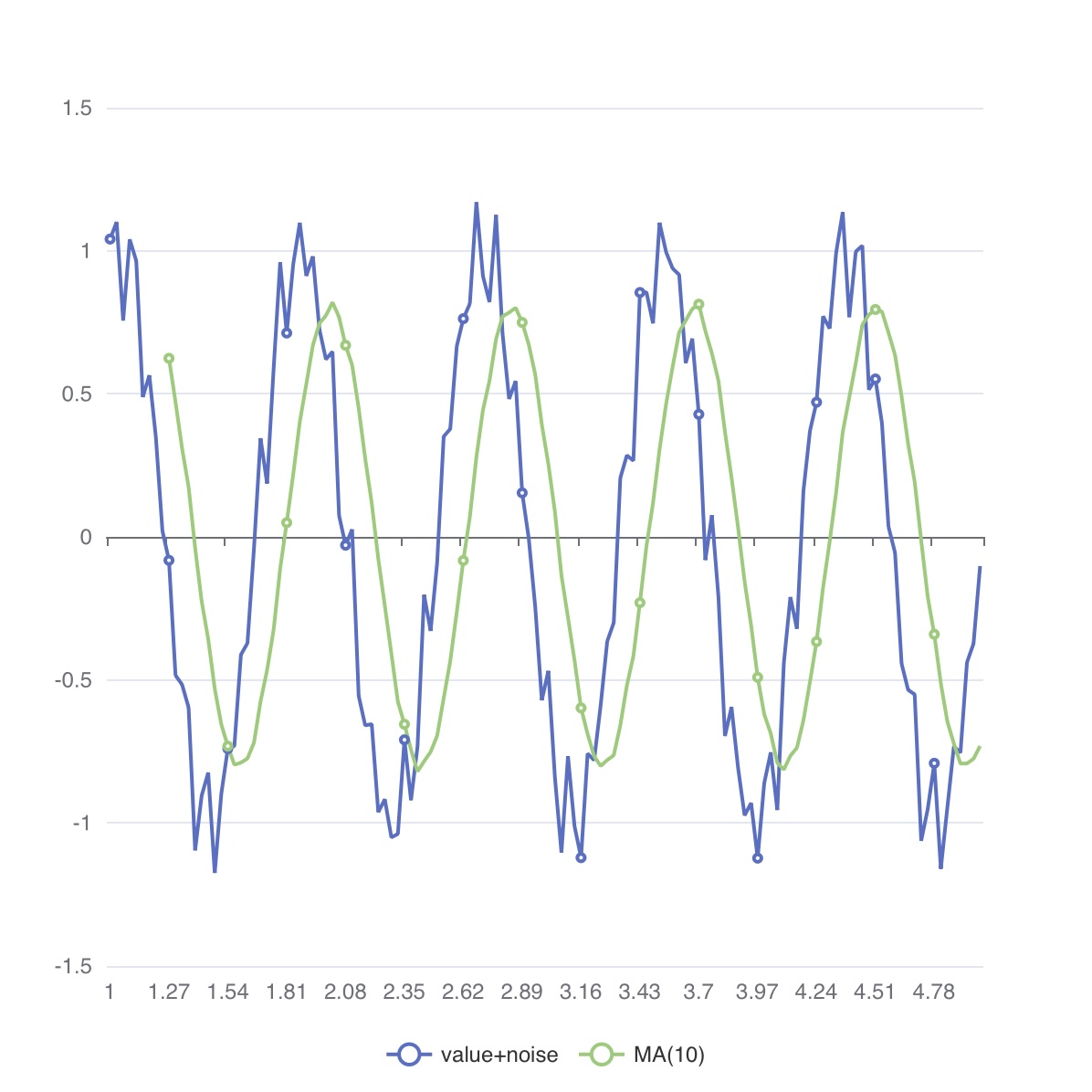
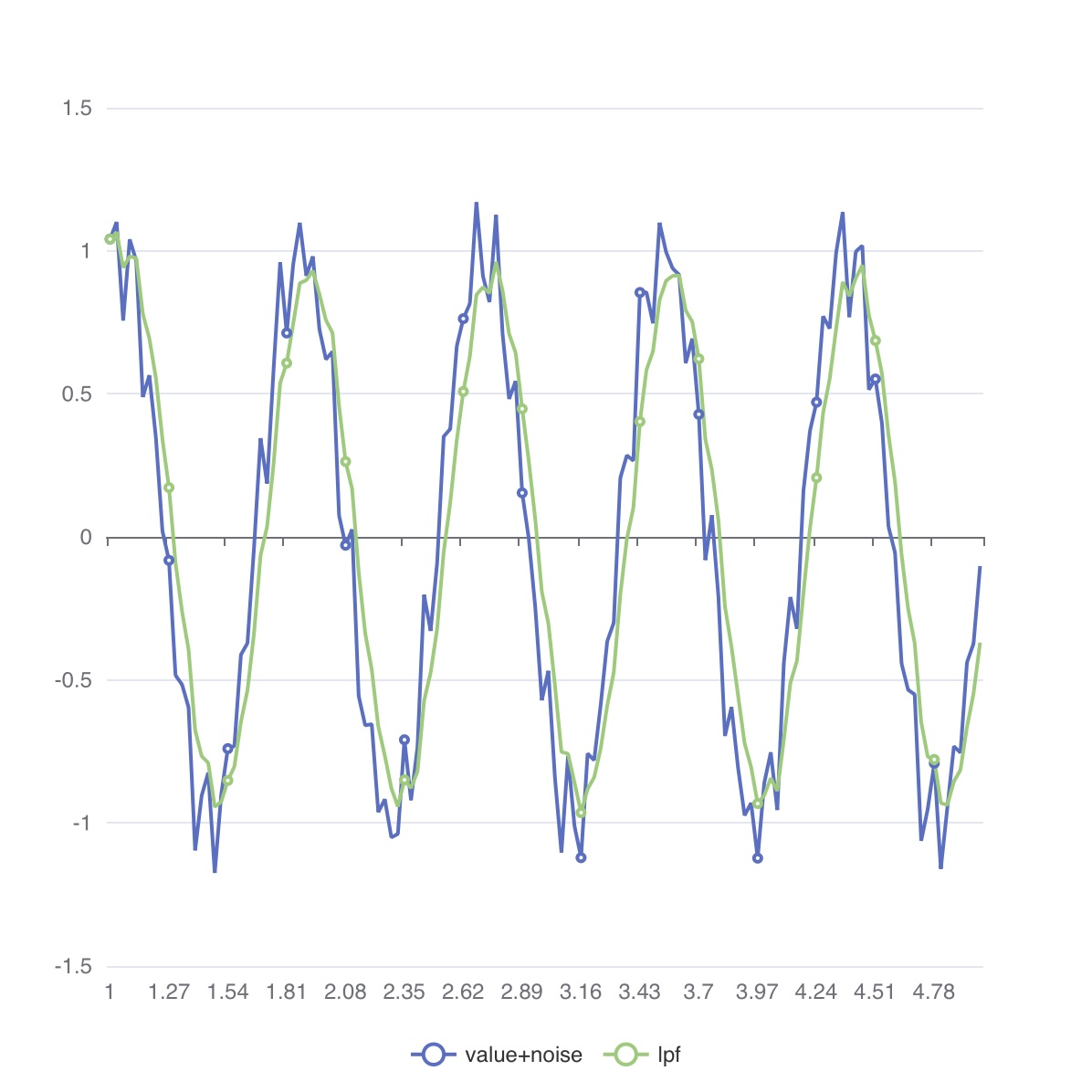
MAP_LOWPASS()
구문: MAP_LOWPATH(idx, value, alpha [, label] )
Since v8.0.15
idxnumber: 값 튜플의 인덱스(0부터 시작)valuenumberalphanumber: 0 < alpha < 1 범위의 계수labelstring: 새로운 컬럼 이름
MAP_LOWPASS는 지정된 위치의 값을 지수 가중 이동 평균(EWMA)으로 교체합니다.
$ 0 < \alpha < 1$ 일 때,
$\overline{x_k} = (1 - \alpha) \overline{x_{k-1}} + \alpha x_k$
| |
- 5행: 노이즈가 포함된 신호를 생성합니다.
- 6행:
alpha = 0.40인 저역 통과 필터를 적용합니다.
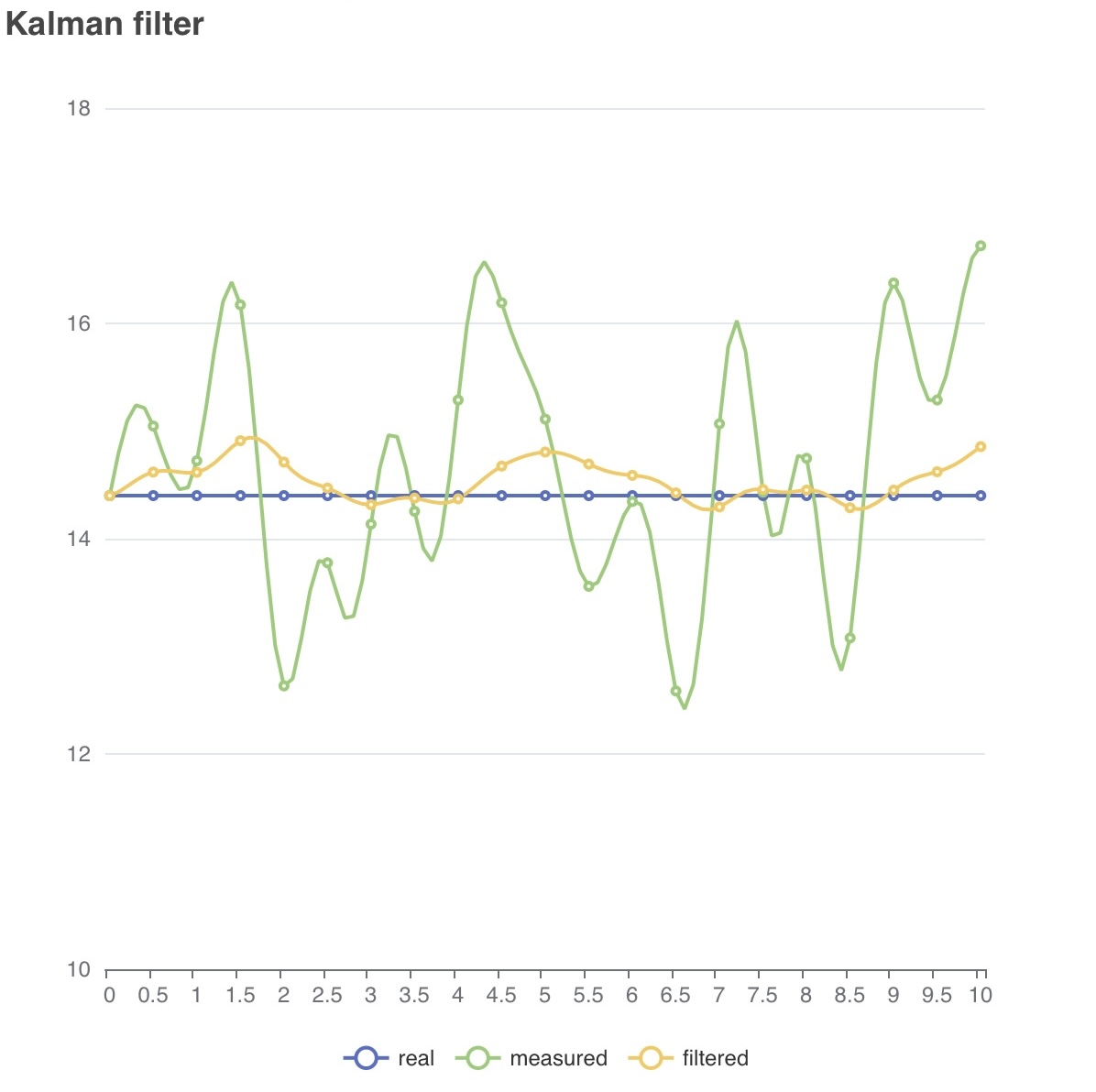
MAP_KALMAN()
구문: MAP_KALMAN(idx, value, model() [, label])
Since v8.0.15
idxnumber: 값 튜플의 인덱스(0부터 시작)valuenumbermodelmodel(initial, progress, observation): 시스템 행렬을 지정합니다.labelstring: 새로운 컬럼 이름
| |
- 4행: 실제 값은 상수
14.4입니다. - 5행: 단순 노이즈를 생성합니다.
- 6행: 실제 값과 노이즈를 합쳐 측정값을 만듭니다.
- 10행: 측정값에 칼만 필터를 적용합니다.
HISTOGRAM()
HISTOGRAM()은 두 가지 방식으로 동작합니다. 입력 값의 범위가 고정되어 있거나 예측 가능한 경우에는 “고정 구간(fixed bins)“을, 값 범위를 알 수 없을 때는 “동적 구간(dynamic bins)“을 사용하면 편리합니다.
Fixed Bins
구문: HISTOGRAM(value, bins [, category] [, order] )
Since v8.0.15
valuenumberbinsbins(min, max, step): 히스토그램 구간 설정categorycategory(name_value): 분류 컬럼orderorder(name…string): 카테고리 순서
HISTOGRAM()은 값들의 분포를 지정한 구간으로 집계합니다. 구간은 최소/최대 값과 분할 수로 설정하며, 실제 값이 범위를 벗어나면 자동으로 하위 또는 상위 구간이 추가됩니다.
| |
low,high,count
0,40,2
40,80,31
80,120,47
120,160,16
160,200,4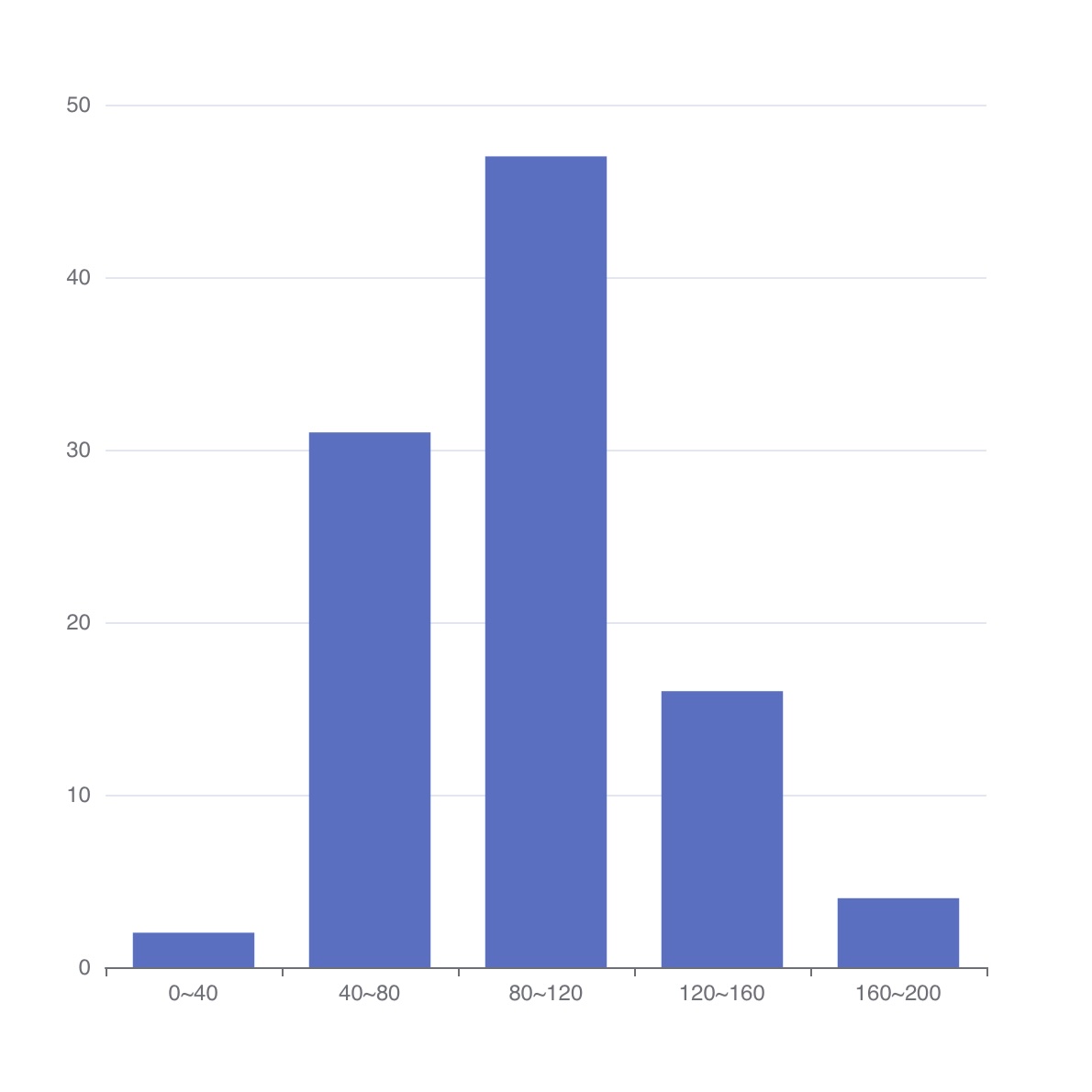
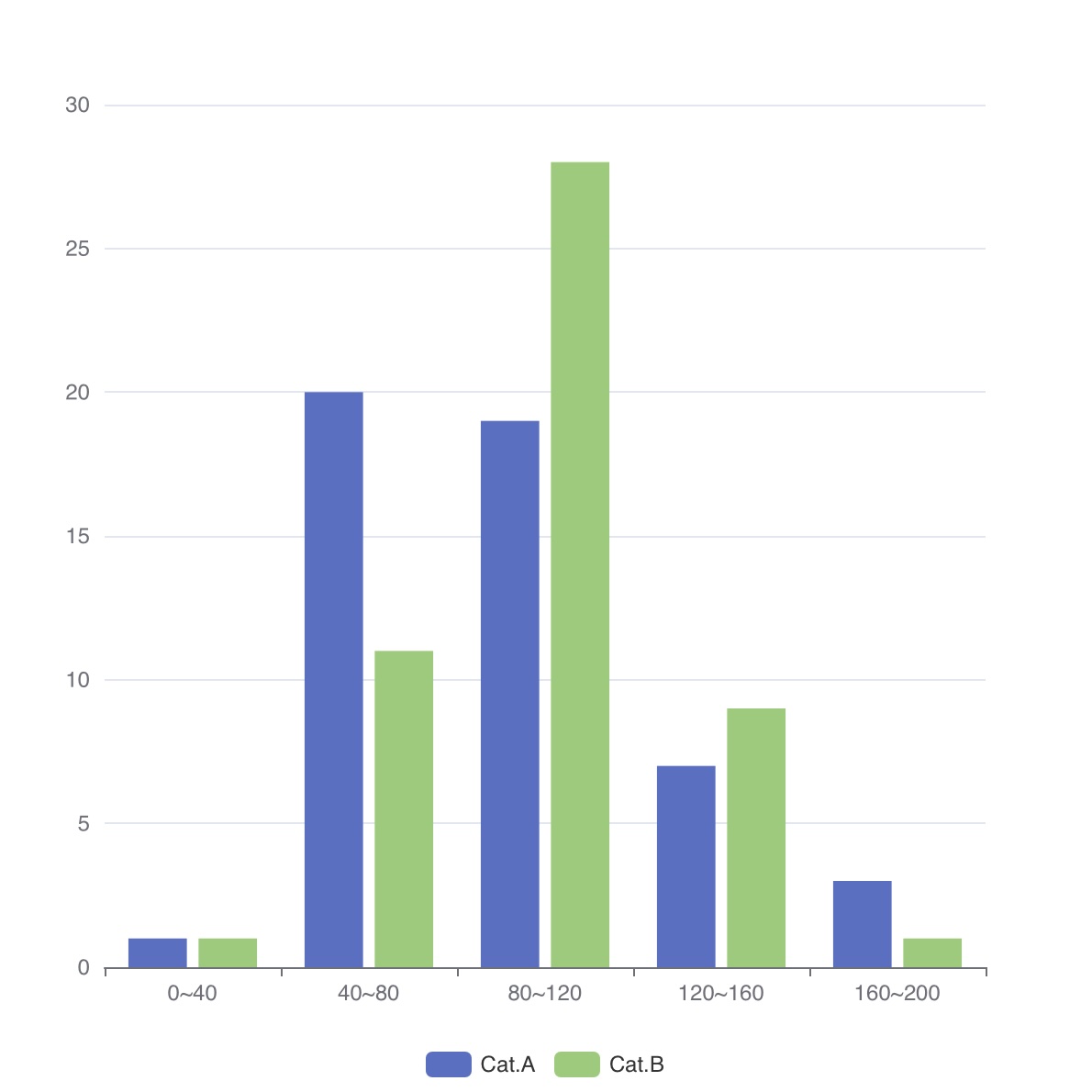
동적 구간
구문: HISTOGRAM(value [, bins(maxBins)] )
Since v8.0.46
valuenumberbinsnumber: 생성할 최대 구간 수(기본값 100)
HISTOGRAM()은 값과 최대 구간 수를 받아 입력 범위에 맞춰 구간을 동적으로 조정합니다.value 컬럼은 각 구간의 평균값을, count 컬럼은 해당 구간에 속한 값의 개수를 나타냅니다.
따라서 value × count는 해당 구간 값들의 합과 동일합니다.
| |
value,count
47,12
75,29
99,29
119,18
156,12BOXPLOT()
구문: BOXPLOT(value, category [, order] [, boxplotInterp] [, boxplotOutput])
Since v8.0.15
valuenumbercategorycategory(name_value): 그룹 구분자orderorder(name…string): 카테고리 순서boxplotOutputboxplotOutput( "” | “chart” | “dict” ): 출력 형식boxplotInterpboxplotInterop(Q1 boolean, Q2 boolean, Q3 boolean): 사분위수 보간 옵션- 자세한 예시는 Michelson & Morley Experiment와 Iris Sepal Length를 참고해 주십시오.
TRANSPOSE()
구문: TRANSPOSE( [fixed(columnIdx...) | columnIdx...] [, header(boolean)] )
Since v8.0.8
CSV나 브리지를 통해 외부 RDBMS에서 데이터를 읽어 올 때, Machbase TAG 테이블 구조에 맞추기 위해 컬럼을 행으로 전환해야 할 때가 있습니다.TRANSPOSE는 여러 컬럼을 가진 레코드를 여러 개의 행으로 변환해 줍니다.
fixed(columnIdx...): 고정으로 유지할 컬럼을 지정합니다. 전환 컬럼과 함께 사용할 수 없습니다.columnIdx...: 전환(transpose)할 컬럼 목록을 지정합니다.fixed()와 함께 사용할 수 없습니다.header(boolean):header(true)로 설정하면 첫 레코드를 헤더로 간주하고, 전환된 레코드에 헤더 값을 새 컬럼으로 추가합니다.
| |
대표적인 사용 예시는 다음과 같습니다.
- 5행: 2, 3, 4번 컬럼을 헤더와 함께 전환합니다.
- 6행: 도시 이름과 전환된 컬럼 이름을 결합합니다.
- 7행: 문자열을 시간으로 변환합니다.
- 8행: 값 문자열을 숫자로 변환합니다.
- 9행: 더 이상 필요 없는 전환된 컬럼 이름을 제거합니다.
TOKYO-TEMPERATURE,1701907200,23
TOKYO-HUMIDITY,1701907200,30
TOKYO-NOISE,1701907200,40
BEIJING-TEMPERATURE,1701907200,24
BEIJING-HUMIDITY,1701907200,50
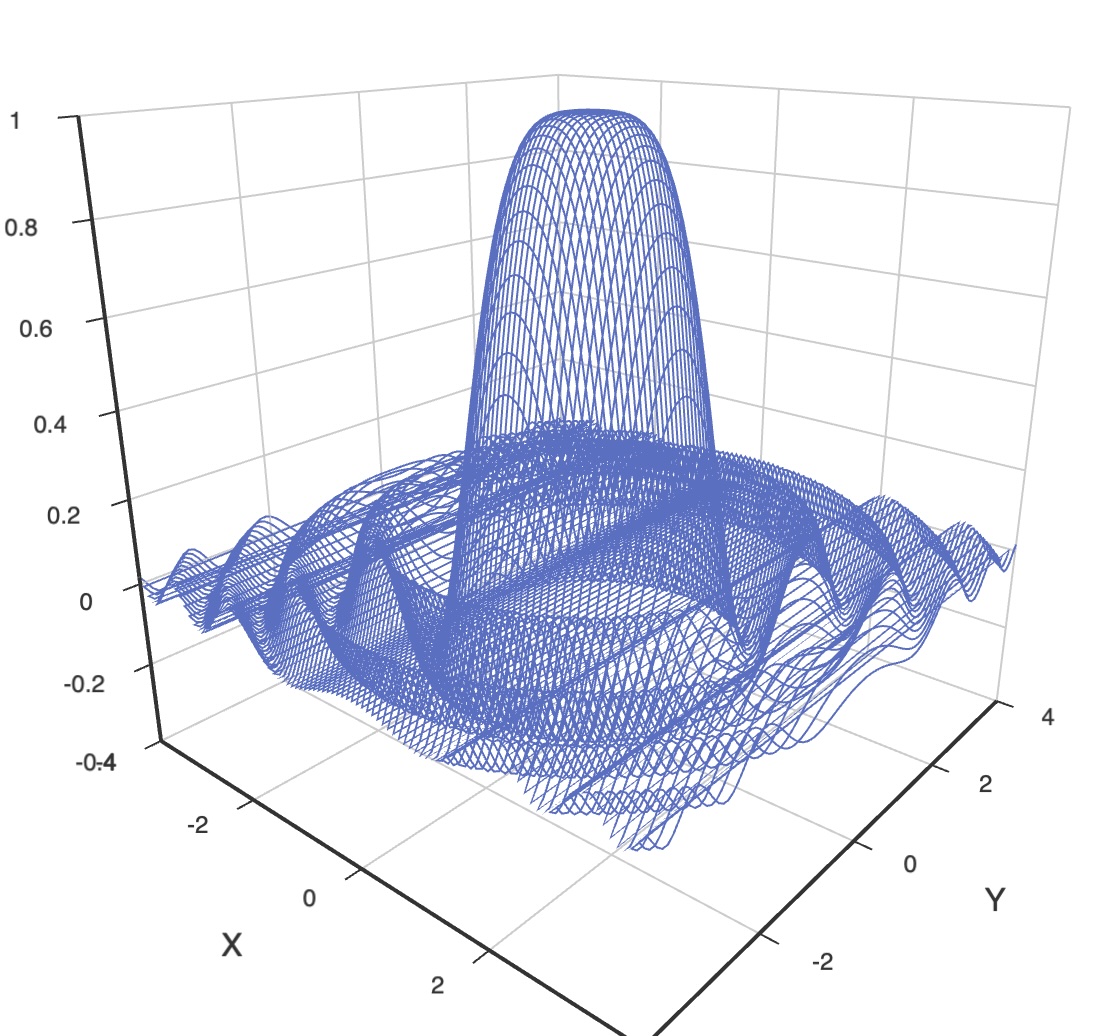
BEIJING-NOISE,1701907200,60FFT()
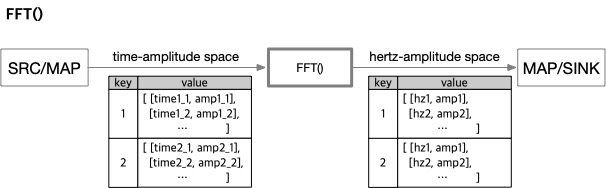
구문: FFT([minHz(value), maxHz(value)])
minHz(value) : 분석에 사용할 최소 주파수maxHz(value) : 분석에 사용할 최대 주파수
입력 레코드의 값이 (time, amplitude) 튜플 배열이라고 가정하고 고속 푸리에 변환(FFT)을 적용합니다.
변환 후에는 같은 키를 유지한 채 (frequency, amplitude) 튜플 배열로 값이 대체됩니다.
예를 들어 입력이 {key: k, value[[t1,a1],[t2,a2],..., [tn,an]]}라면, 결과는 {key: k, value[[F1,A1],[F2,A2],..., [Fm,Am]]} 형태가 됩니다.
| |
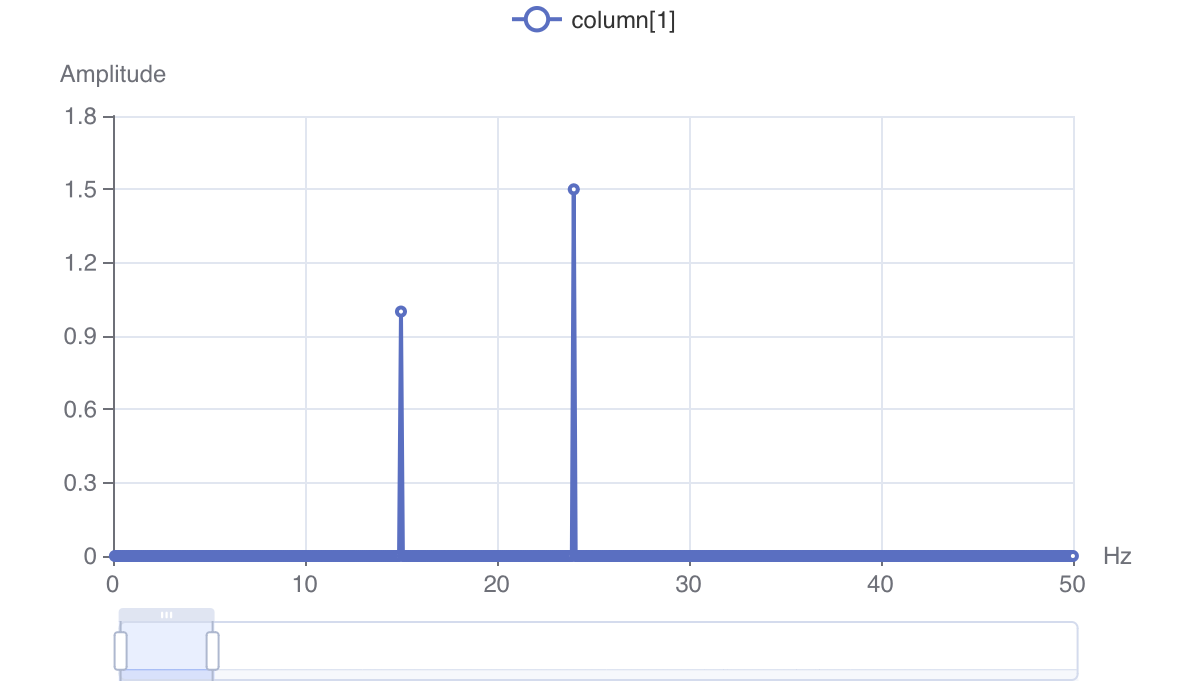
3D 시각화 예시를 포함한 자세한 설명은 FFT() 문서를 참고해 주십시오.
WHEN()
구문: WHEN(condition, doer)
Since v8.0.7
conditionbooleandoerdoer
WHEN은 조건이 참일 때 지정한 doer 동작을 실행합니다.
레코드 흐름에는 영향을 주지 않으며, 정의된 부수 효과 작업만 수행합니다.
doLog()
구문: doLog(args...)
Since v8.0.7
웹 콘솔에 로그 메시지를 출력합니다.
| |
doHttp()
구문: doHttp(method, url, body [, header...])
Since v8.0.7
methodstringurlstringbodystringheaderstring: 선택 헤더
doHttp는 지정한 메서드·URL·본문·헤더로 HTTP 요청을 전송합니다.
활용 예시
- 특정 HTTP 엔드포인트로 이벤트를 알립니다.
| |
- 현재 레코드를 CSV(기본 형식)로 전송합니다.
| |
- 현재 레코드를 사용자 정의 JSON 형식으로 전송합니다.
| |
do()
구문: do(args..., { sub-flow-code })
Since v8.0.7
do는 전달받은 args... 인자를 사용해 하위 플로우 코드를 실행합니다.
WHEN()은 특정 조건에서 부수 효과를 수행하기 위한 기능임을 기억해 주십시오.
따라서 WHEN 안의 하위 플로우는 CSV, JSON, CHART_*처럼 출력 스트림에 결과를 내보내는 SINK를 사용할 수 없습니다. 하위 플로우에서 이러한 SINK를 호출해도 출력은 무시되고 경고 메시지가 표시됩니다.
하위 플로우에서는 출력 스트림과 무관한 INSERT, APPEND가 효과적인 SINK입니다. 이들을 사용하면 메인 TQL 흐름과 다른 테이블에 값을 기록할 수 있습니다. 별도의 처리가 필요 없다면 DISCARD()를 사용해 경고 없이 레코드를 버릴 수 있습니다.
| |
위 로그는 두 가지 중요한 사실을 보여 줍니다.
- 메인 플로우는 하위 플로우가 작업을 마칠 때까지 대기합니다.
- 조건에 맞는 레코드마다 하위 플로우가 실행됩니다.
2023-12-02 07:54:42.160 TRACE 0xc000bfa580 Task compiled FAKE() → WHEN() → CSV()
2023-12-02 07:54:42.160 TRACE 0xc000bfa840 Task compiled ARGS() → WHEN() → DISCARD()
2023-12-02 07:54:42.160 INFO 0xc000bfa840 Greetings: 你好 idx: 2
2023-12-02 07:54:42.160 DEBUG 0xc000bfa840 Task elapsed 254.583µs
2023-12-02 07:54:42.161 TRACE 0xc000bfa9a0 Task compiled ARGS() → WHEN() → DISCARD()
2023-12-02 07:54:42.161 INFO 0xc000bfa9a0 Greetings: 世界 idx: 4
2023-12-02 07:54:42.161 DEBUG 0xc000bfa9a0 Task elapsed 190.552µs
2023-12-02 07:54:42.161 DEBUG 0xc000bfa580 Task elapsed 1.102681ms활용 예시
하위 플로우가 인자 외의 다른 데이터를 조회할 때는 args([idx]) 옵션 함수로 전달된 인자를 다시 참조할 수 있습니다.
- 하위 플로우 인자를 사용해 쿼리를 실행합니다.
// pseudo code
// ...
WHEN( condition,
do(value(0), {
SQL(`select time, value from table where name = ?`, args(0))
// ... some map functions...
INSERT(...)
})
)
// ...
- 외부 웹 서버에서 CSV 파일을 가져옵니다.
// pseudo code
// ...
WHEN( condition,
do(value(0), value(1), {
CSV( file( strSprintf("https://exmaple.com/data_%s.csv?id=%s", args(0), escapeParam(args(1)) )))
WHEN(true, doHttp("POST", "http://my_server", value()))
DISCARD()
})
)
// ...
FLATTEN()
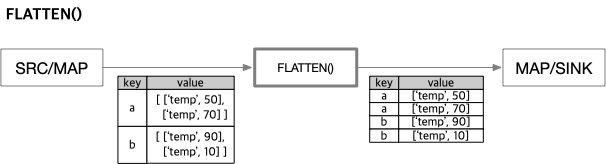
구문: FLATTEN()
GROUPBYKEY()와 반대로 동작하며, 다차원 튜플을 가진 레코드를 각 요소별로 분해해 차원을 낮춘 여러 레코드로 만듭니다.
예를 들어 입력이 {key:k, value:[[v1,v2],[v3,v4],...,[vx,vy]]}라면 결과는 {key:k, value:[v1, v2]}, {key:k, value:[v3, v4]}, …, {key:k, value:[vx, vy]}가 됩니다.
MAPKEY()

구문: MAPKEY( newkey )
현재 키 값을 지정한 새 키로 교체합니다.
| |
1701343504143299000,TAG0,1628694000000000000,10
1701343504143303000,TAG0,1628780400000000000,11
1701343504143308000,TAG0,1628866800000000000,12
1701343504143365000,TAG0,1628953200000000000,13
1701343504143379000,TAG0,1629039600000000000,14
1701343504143383000,TAG0,1629126000000000000,15PUSHKEY()

구문: PUSHKEY( newkey )
모든 레코드의 키를 지정한 값으로 바꾸면서 기존 키를 값 튜플의 첫 번째 요소로 밀어 넣습니다.
예를 들어 {key: 'k1', value: [v1, v2]}에 PUSHKEY(newkey)를 적용하면 {key: newkey, values: [k1, v1, v1]} 형태로 변환됩니다.
| |
1701343504143299000,TAG0,1628694000000000000,10
1701343504143303000,TAG0,1628780400000000000,11
1701343504143308000,TAG0,1628866800000000000,12
1701343504143365000,TAG0,1628953200000000000,13
1701343504143379000,TAG0,1629039600000000000,14
1701343504143383000,TAG0,1629126000000000000,15POPKEY()

구문: POPKEY( [idx] )
현재 키를 제거하고 값 튜플의 idx번째 요소를 새 키로 승격합니다.
예를 들어 {key: k, value: [v1, v2, v3]}에 POPKEY(1)을 적용하면 {key: v2, value:[v1, v3]}가 됩니다.
인자를 생략하면 POPKEY(0)과 동일하게 작동해 첫 번째 값을 키로 승격합니다.
| |
1628694000000000000,10
1628780400000000000,11
1628866800000000000,12
1628953200000000000,13
1629039600000000000,14
1629126000000000000,15GROUPBYKEY()

구문: GROUPBYKEY( [lazy(boolean)] )
lazy(boolean): 기본값false일 때는 이전 레코드와 키가 달라지는 즉시 그룹화된 레코드를 반환합니다.true로 지정하면 입력 스트림이 끝날 때까지 대기합니다.
GROUPBYKEY는 GROUP( by( key() ) )와 동일하게 동작합니다.
THROTTLE()
구문: THROTTLE(tps)
Since v8.0.8
tpsnumber: 초당 전달할 레코드 수
THROTTLE은 지정한 tps에 맞추어 레코드 전달 속도를 지연시킵니다.
저장된 데이터(CSV 등)를 일정 주기로 흘려보내 센서 장치를 시뮬레이션할 때 유용합니다.
| |
- 콘솔 로그에서
"tick"메시지는 약 200ms 간격(초당 5건)으로 출력됩니다.
2023-12-07 09:33:30.131 TRACE 0x14000f88b00 Task compiled FAKE() → THROTTLE() → WHEN() → CSV()
2023-12-07 09:33:30.332 INFO 0x14000f88b00 ===>tick 1
2023-12-07 09:33:30.533 INFO 0x14000f88b00 ===>tick 2
2023-12-07 09:33:30.734 INFO 0x14000f88b00 ===>tick 3
2023-12-07 09:33:30.935 INFO 0x14000f88b00 ===>tick 4
2023-12-07 09:33:31.136 INFO 0x14000f88b00 ===>tick 5
2023-12-07 09:33:31.136 DEBUG 0x14000f88b00
Task elapsed 1.005070167sSCRIPT()
사용자 정의 스크립트 언어를 지원합니다.
자세한 예시는 SCRIPT 문서를 참고해 주십시오.