MAP
MAP functions are the core of the transforming data.
TAKE()

Syntax: TAKE( [offset,] n )
Takes first n records and stop the stream.
offsetnumber optional, take records from the offset. (default 0 when omitted) Since v8.0.6nnumber specify how many records to be taken.
| |
TAG0,1628694000000000000,10
TAG0,1628780400000000000,11DROP()

Syntax: DROP( [offset,] n )
Ignore first n records, it simply drops the n records.
offsetnumber optional, drop records from the offset. (default 0 when omitted) Since v8.0.6nnumber specify how many records to be dropped.
| |
TAG0,1628953200000000000,13
TAG0,1629039600000000000,14
TAG0,1629126000000000000,15FILTER()

Syntax: FILTER( condition )
Apply the condition statement on the incoming record, then it pass the record only if the condition is true.
For example, if an original record was {key: k1, value[v1, v2]} and apply FILTER(count(V) > 2), it simply drop the record. If the condition was FILTER(count(V) >= 2), it pass the record to the next function.
| |
TAG0,1628694000000000000,10
TAG0,1628780400000000000,11FILTER_CHANGED()
Syntax: FILTER_CHANGED( value [, retain(time, duration)] [, useFirstWithLast()] )
Since v8.0.15
retain(time, duration)useFirstWithLast(boolean)
It passes only the value has been changed from the previous.
The first record is always passed, use DROP(1) after FILTER_CHANGED() to discard the first record.
If retain() option is specified, the records that keep the changed value for the given duration based time, are passed.
| |
A,1692329338,1
B,1692329340,3
C,1692329346,9
D,1692329347,9.1SET()
Syntax: SET(name, expression)
Since v8.0.12
namekeyword variable nameexpressionexpression value
SET defines a record-scoped variable with given name and value. If a new variable var is defined as SET(var, 10), it can be referred as $var. Because the variables are not a part of the values, it is not included in the final result of SINK.
| |
0,1
0.5,6
1,11GROUP()
Syntax: GROUP( [lazy(boolean),] by [, aggregators...] )
Since v8.0.7
lazy(boolean)If it setfalsewhich is default, GROUP() yields new aggregated record when the value ofby()has changed from previous record. If it settrue, GROUP() waits the end of the input stream before yield any record.by(value [, label])The value how to group the values.aggregatorsarray of aggregator Aggregate functions
Group aggregation function, please refer to the GROUP() section for the detail description.
PUSHVALUE()

Syntax: PUSHVALUE( idx, value [, name] )
Since v8.0.5
idxnumber Index where newValue insert at. (0 based)valueexpression New valuenamestring column’s name (default ‘column’)
Insert the given value (new column) into the current values.
| |
0.0,0
0.5,5
1.0,10POPVALUE()

Syntax: POPVALUE( idx [, idx2, idx3, ...] )
Since v8.0.5
idxnumber array of indexes that will removed from values
It removes column of values that specified by idxes from value array.
| |
0
5
10MAPVALUE()

Syntax: MAPVALUE( idx, newValue [, newName] )
idxnumber Index of the value tuple. (0 based)newValueexpression New valuenewNamestring change column’s name with given string
MAPVALUE() replaces the value of the element at the given index. For example, MAPVALUE(0, value(0)*10) replaces a new value that is 10 times of the first element of value tuple.
If the idx is out of range, it works as PUSHVALUE() does. MAPVALUE(-1, value(1)+'_suffix') inserts a new string value that concatenates ‘_suffix’ with the 2nd element of value.
| |
0
5
10An example use of mathematic operation with MAPVALUE.
| |

MAP_DIFF()
Syntax: MAP_DIFF( idx, value [, newName] )
Since v8.0.8
idxnumber Index of the value tuple. (0 based)valuenumbernewNamestring change column’s name with given string
MAP_DIFF() replaces the value of the element at the given index with difference between current and previous values (current - previous).
| |
VALUE,DIFF
-0.693,NULL
-0.251,0.442
0.054,0.305
0.288,0.234
0.477,0.189
0.636,0.159
0.773,0.137
0.894,0.121
1.001,0.108
1.099,0.097MAP_ABSDIFF()
Syntax: MAP_ABSDIFF( idx, value [, label] )
Since v8.0.8
idxnumber Index of the value tuple. (0 based)valuenumberlabelstring change column’s label with given string
MAP_ABSDIFF() replaces the value of the element at the given index with absolute difference between current and previous value abs(current - previous).
MAP_NONEGDIFF()
Syntax: MAP_NONEGDIFF( idx, value [, label] )
Since v8.0.8
idxnumber Index of the value tuple. (0 based)valuenumberlabelstring change column’s label with given string
MAP_NONEGDIFF() replaces the value of the element at the given index with difference between current and previous value (current - previous).
If the difference is less than zero it applies zero instead of a negative value.
MAP_AVG()
Syntax: MAP_AVG(idx, value [, label] )
Since v8.0.15
idxnumber Index of the value tuple. (0 based)valuenumberlabelstring change column’s label with given string
MAP_AVG sets the value of the element at the given index with a average of values which is the averaging filter.
When $k$ is number of data.
Let $\alpha = \frac{1}{k}$
$\overline{x_k} = (1 - \alpha) \overline{x_{k-1}} + \alpha x_k$
| |

MAP_MOVAVG()
Syntax: MAP_MOVAVG(idx, value, window [, label] )
Since v8.0.8
idxnumber Index of the value tuple. (0 based)valuenumberwindownumber specifies how many records it accumulates.labelstring change column’s label with given string
MAP_MOVAVG sets the value of the element at the given index with a moving average of values by given window count.
If values are not accumulated enough to the window, it applies sum/count_of_values instead.
If all incoming values are NULL (or not a number) for the last window count, it applies NULL.
If some accumulated values are NULL (or not a number), it makes average value from only valid values excluding the NULLs.
| |
- Line 5 : Generate signal value mxied with noise
- Line 6 : Moving average with windows size is 10

MAP_LOWPASS()
Syntax: MAP_LOWPATH(idx, value, alpha [, label] )
Since v8.0.15
idxnumber Index of the value tuple. (0 based)valuenumberalphanumber, 0 < alpha < 1labelstring change column’s label with given string
MAP_LOWPASS sets the value of the elment at the given index with exponentially weighted moving average.
When $ 0 < \alpha < 1$
$\overline{x_k} = (1 - \alpha) \overline{x_{k-1}} + \alpha x_k$
| |
- Line 5: Generate signal value with noise
- Line 6: Apply low pass filter with alpha =
0.40

MAP_KALMAN()
Syntax: MAP_KALMAN(idx, value, model() [, label])
Since v8.0.15
idxnumber Index of the value tuple. (0 based)valuenumbermodelmodel(initial, progress, observation) Set system matriceslabelstring change column’s label with given string
| |
- Line 4: The real value is a constant
14.4 - Line 5: Random(simple x) noise
- Line 6: Artificially generated meaured value value+noise.
- Line 10: Apply Kalman filter on the meatured values.

HISTOGRAM()
There are two types of HISTOGRAM(). The first type is “fixed bins” which is useful when the input value range (min to max) is predictable or fixed. The second type is “dynamic bins” which is useful when the value ranges are unknown.
Fixed Bins
Syntax: HISTOGRAM(value, bins [, category] [, order] )
Since v8.0.15
valuenumberbinsbins(min, max, step) histogram bin configuration.categorycategory(name_value)orderorder(name…string) category order
HISTOGRAM() takes values and count the distribution of the each bins, the bins are configured by min/max range of the value and the count of bins.
If the actual value comes in the out of the min/max range, HISTOGRAM() adds lower or higher bins automatically.
| |
low,high,count
0,40,2
40,80,31
80,120,47
120,160,16
160,200,4

Dynamic Bins
Syntax: HISTOGRAM(value [, bins(maxBins)] )
Since v8.0.46
valuenumberbinsnumber specifies the maximum number of bins. The default is 100 if not specified.
HISTOGRAM() takes values and a maximum number of bins.
The bins are dynamically adjusted based on the input values and can expand up to the specified bins(maxBins).
The resulting value column represents the average value of each bin,
while the count column indicates the number of values within that range.
Thus, the product of value and count for a bin equals the sum of the values within that bin.
| |
value,count
47,12
75,29
99,29
119,18
156,12BOXPLOT()
Syntax: BOXPLOT(value, category [, order] [, boxplotInterp] [, boxplotOutput])
Since v8.0.15
valuenumbercategorycategory(name_value)orderorder(name…string) category orderboxplotOutputboxplotOutput( "" | “chart” | “dict” )boxplotInterpboxplotInterop(Q1 boolean, Q2 boolean, Q3 boolean)
TRANSPOSE()
Syntax: TRANSPOSE( [fixed(columnIdx...) | columnIdx...] [, header(boolean)] )
Since v8.0.8
When TQL loads data from CSV or external RDBMS via ‘bridge’d SQL query, it may require to transpose columns to fit the record shape to a MACHBASE TAG table.
TRANSPOSE produce multiple records from a record that has multiple columns.
fixed(columnIdx...)specify which columns are “fixed”, this can not mix-use with transposed columns.columnIdx...specify multiple columns which are “transposed”, this can not mix-use with “fixed()”.header(boolean)if it setheader(true),TRANSPOSEconsider the first record is the header record. And it produce the header of the transposed column records as a new column.
| |
This example is a common use case.
- Line 5: Transpose column 2, 3, 4 with its header.
- Line 6: Concatenate city and transposed column name (from header).
- Line 7: Convert string to time.
- Line 8: Convert value string into number.
- Line 9: Remove transposed column names, no more needed.
TOKYO-TEMPERATURE,1701907200,23
TOKYO-HUMIDITY,1701907200,30
TOKYO-NOISE,1701907200,40
BEIJING-TEMPERATURE,1701907200,24
BEIJING-HUMIDITY,1701907200,50
BEIJING-NOISE,1701907200,60FFT()

Syntax: FFT([minHz(value), maxHz(value)])
minHz(value) minimum Hz for analysismaxHz(value) maximum Hz for analysis
It assumes value of the incoming record is an array of time,amplitude tuples, then applies Fast Fourier Transform on the array and replaces the value with an array of frequency,amplitude tuples. The key remains same.
For example, if the incoming record was {key: k, value[ [t1,a1],[t2,a2],...[tn,an] ]}, it transforms the value to {key:k, value[ [F1,A1], [F2,A2],...[Fm,Am] ]}.
| |
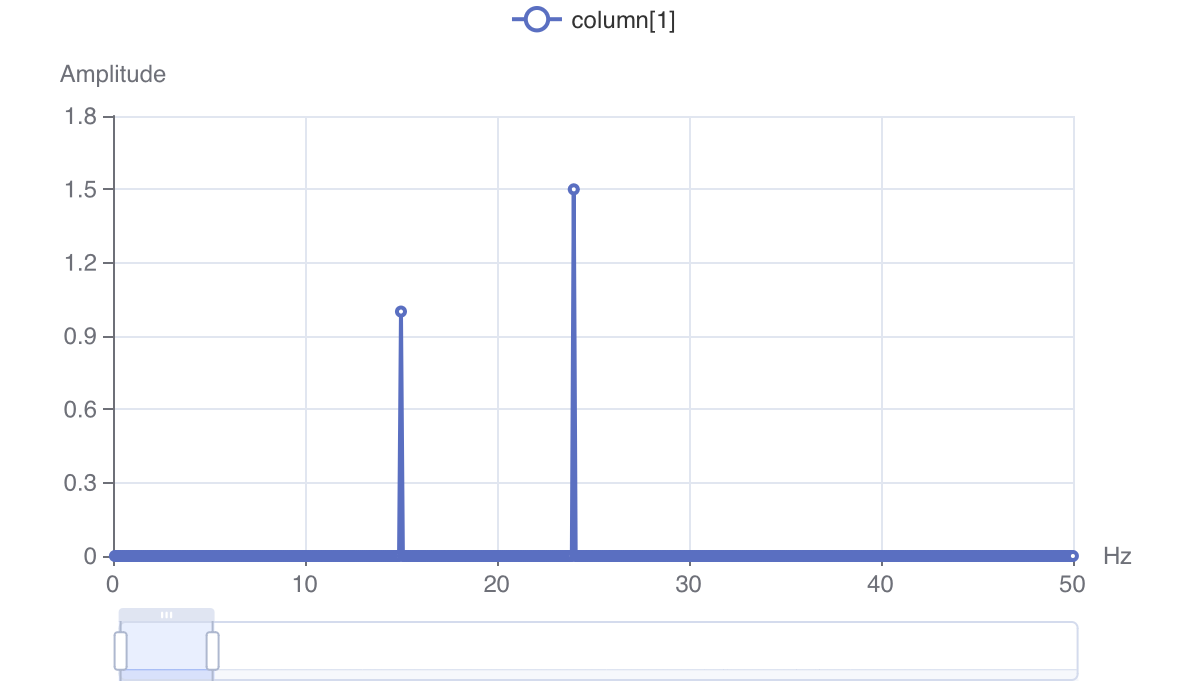
Please refer to the FFT() section for the more information including 3D sample codes
WHEN()
Syntax: WHEN(condition, doer)
Since v8.0.7
conditionbooleandoerdoer
WHEN runs doer action if the given condition is true.
This function does not affects the flow of records, it just executes the defined side effect work.
doLog()
Syntax: doLog(args...)
Since v8.0.7
Prints out log message on the web console.
| |
doHttp()
Syntax: doHttp(method, url, body [, header...])
Since v8.0.7
methodstringurlstringbodystringheaderstring optional
doHttp requests the http endpoints with given method, url, body and headers.
Use cases
- Notify an event to the specific HTTP endpoint.
| |
- Post the current record to the specific HTTP endpoint in CSV which is default format of
doHttp.
| |
- Post the current record in a custom JSON format to the specific HTTP endpoint.
| |
do()
Syntax: do(args..., { sub-flow-code })
Since v8.0.7
do executes the given sub flow code with passing args... arguments.
It is important to keep in mind that WHEN() is only for executing a side effect job on a certain condition.
WHEN-do sub flow cannot affects to the main flow, which means it cannot use SINKs that produce result on output stream like CSV, JSON, and CHART_*. The output of a sub flow will be ignored silently, any writing attempts from a sink are ignored and showing warning messages.
Effective SINKs in a sub flow may be INSERT and APPEND which is not related with output stream, so that it can write the specific values on a different table from main TQL flow. Otherwise use DISCARD() sink, it silently discards any records in the sub flow without warning messages.
| |
The log messages of the above code shows the two important points.
- The main flow is blocked and waits until its sub flow finishes the job.
- The sub flow is executed every time for a record that matches the condition.
2023-12-02 07:54:42.160 TRACE 0xc000bfa580 Task compiled FAKE() → WHEN() → CSV()
2023-12-02 07:54:42.160 TRACE 0xc000bfa840 Task compiled ARGS() → WHEN() → DISCARD()
2023-12-02 07:54:42.160 INFO 0xc000bfa840 Greetings: 你好 idx: 2
2023-12-02 07:54:42.160 DEBUG 0xc000bfa840 Task elapsed 254.583µs
2023-12-02 07:54:42.161 TRACE 0xc000bfa9a0 Task compiled ARGS() → WHEN() → DISCARD()
2023-12-02 07:54:42.161 INFO 0xc000bfa9a0 Greetings: 世界 idx: 4
2023-12-02 07:54:42.161 DEBUG 0xc000bfa9a0 Task elapsed 190.552µs
2023-12-02 07:54:42.161 DEBUG 0xc000bfa580 Task elapsed 1.102681msUse cases
When sub flow retrieves data from other than its arguments, it can access the arguments with args([idx]) option function.
- Execute query with sub flow’s arguments.
// pseudo code
// ...
WHEN( condition,
do(value(0), {
SQL(`select time, value from table where name = ?`, args(0))
// ... some map functions...
INSERT(...)
})
)
// ...
- Retrieve csv file from external web server
// pseudo code
// ...
WHEN( condition,
do(value(0), value(1), {
CSV( file( strSprintf("https://exmaple.com/data_%s.csv?id=%s", args(0), escapeParam(args(1)) )))
WHEN(true, doHttp("POST", "http://my_server", value()))
DISCARD()
})
)
// ...
FLATTEN()

Syntax: FLATTEN()
It works the opposite way of GROUPBYKEY(). Take a record whose value is multi-dimension tuple, produces multiple records for each elements of the tuple reducing the dimension.
For example, if an original record was {key:k, value:[[v1,v2],[v3,v4],...,[vx,vy]]}, it produces the new multiple records as {key:k, value:[v1, v2]}, {key:k, value:{v3, v4}}…{key:k, value:{vx, vy}}.
MAPKEY()

Syntax: MAPKEY( newkey )
Replace current key value with the given newkey.
| |
1701343504143299000,TAG0,1628694000000000000,10
1701343504143303000,TAG0,1628780400000000000,11
1701343504143308000,TAG0,1628866800000000000,12
1701343504143365000,TAG0,1628953200000000000,13
1701343504143379000,TAG0,1629039600000000000,14
1701343504143383000,TAG0,1629126000000000000,15PUSHKEY()

Syntax: PUSHKEY( newkey )
Apply new key on each record. The original key is push into value tuple.
For example, if an original record was {key: 'k1', value: [v1, v2]} and applied PUSHKEY(newkey), it produces the updated record as {key: newkey, values: [k1, v1, v1]}.
| |
1701343504143299000,TAG0,1628694000000000000,10
1701343504143303000,TAG0,1628780400000000000,11
1701343504143308000,TAG0,1628866800000000000,12
1701343504143365000,TAG0,1628953200000000000,13
1701343504143379000,TAG0,1629039600000000000,14
1701343504143383000,TAG0,1629126000000000000,15POPKEY()

Syntax: POPKEY( [idx] )
Drop current key of the record, then promote idxth element of tuple as a new key.
For example, if an original record was {key: k, value: [v1, v2, v3]} and applied POPKEY(1), it produces the updated record as {key: v2, value:[v1, v3]}.
if use POPKEY() without argument it is equivalent with POPKEY(0) which is promoting the first element of the value tuple as the key.
| |
1628694000000000000,10
1628780400000000000,11
1628866800000000000,12
1628953200000000000,13
1629039600000000000,14
1629126000000000000,15GROUPBYKEY()

Syntax: GROUPBYKEY( [lazy(boolean)] )
lazy(boolean)If it setfalsewhich is default, GROUPBYKEY() yields new grouped record when the key of incoming record has changed from previous record. If it settrue, GROUPBYKEY() waits the end of the input stream before yield any record.
GROUPBYKEY is equivalent expression with GROUP( by( key() ) ).
THROTTLE()
Syntax: THROTTLE(tps)
Since v8.0.8
tpsnumber specify in number of records per a second.
THROTTLE relays a record to the next step with delay to fit to the specified tps.
It makes data flow which has a certain period from stored data (e.g a CSV file),
so that simulates a sensor device that sends measurements by periods.
| |
- At console log, each log time of “tick” message has 200ms. difference (5 per a second).
2023-12-07 09:33:30.131 TRACE 0x14000f88b00 Task compiled FAKE() → THROTTLE() → WHEN() → CSV()
2023-12-07 09:33:30.332 INFO 0x14000f88b00 ===>tick 1
2023-12-07 09:33:30.533 INFO 0x14000f88b00 ===>tick 2
2023-12-07 09:33:30.734 INFO 0x14000f88b00 ===>tick 3
2023-12-07 09:33:30.935 INFO 0x14000f88b00 ===>tick 4
2023-12-07 09:33:31.136 INFO 0x14000f88b00 ===>tick 5
2023-12-07 09:33:31.136 DEBUG 0x14000f88b00
Task elapsed 1.005070167sSCRIPT()
Supporting user defined script language.
See SCRIPT section for the details with examples.